缓存淘汰算法之LRU
说到缓存,就必须先了解下计算机的存储器层次结构。
存储器层次结构的主要思想是上一层的存储器作为低一层存储器的高速缓存。
计算机系统中的存储设备都被组织成了一个存储器层次结构,从上至下,设备的访问速度越来越慢、容量越来越大,并且越便宜。
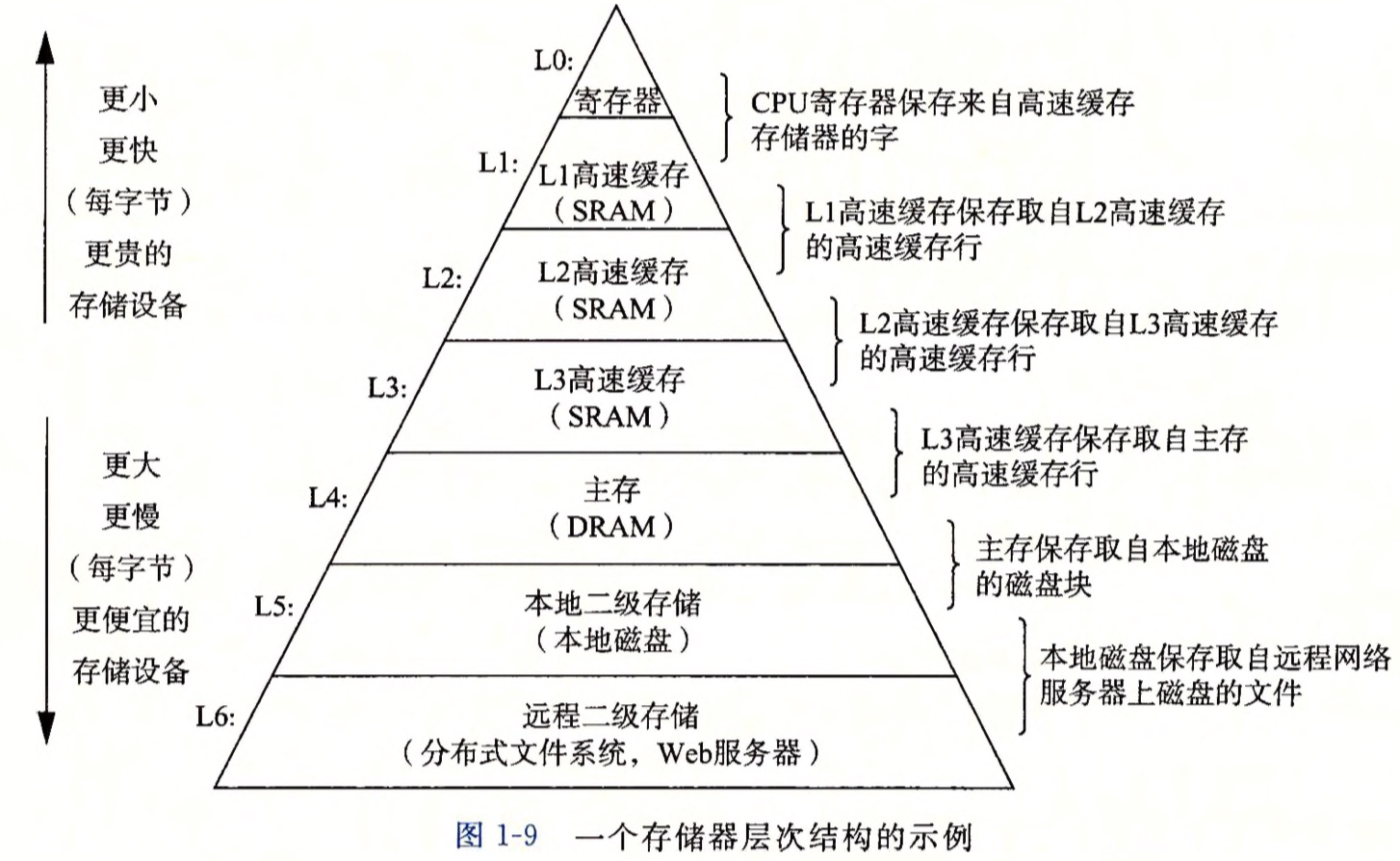
高层的空间速度快容量小,为了充分利用,就必须有个数据替换的规则,决定数据的去留。这就是所谓的缓存淘汰算法。
常见的方法
- 先进先出算法(FIFO):最先进入的内容作为替换对象
- 最近最少使用算法(LFU):最近最少使用的内容作为替换对象
- 最久未使用算法(LRU):最久没有访问的内容作为替换对象
- 非最近使用算法(NMRU):在最近没有使用的内容中随机选择一个作为替换对象
LRU 原理
Least Recently used(LRU) 是最常用的缓存淘汰算法,一般译为“最近最少使用”,不太贴切,其实应该是“最不是最近使用”,也就是将最近一次访问时间最远的数据淘汰掉。
LRU正好体现了时间局部性,也就是,如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
既然是缓存自然需要数据结构记录key和value,可以使用hashmap来存储,查询和设置的复杂度为O(1)。
同时还需要记录数据最近一次访问时间的次序,可以想到用线性结构存储,由于频繁插入删除,可以用链表实现,新数据在头部,老数据在尾部。
由于需要频繁删除数据,而单向链表没有记录前驱节点信息,需要遍历链表,复杂度为O(N),所以使用双向链表。
具体的原则
- 新数据插入到链表头部,并存入hashmap(value为链表节点指针);
- 查找hashmap,当key命中,则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃,删除hashmap对应key;
LRU的不足
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
缓存污染,是指系统将不常用的数据从内存移到缓存,造成常用数据的挤出,降低了缓存效率的现象。
常见改进算法有LFU,LRU-K
Python 实现
首先需要实现双向链表,引入头节点,并将链表首未连在一起,这样插入和删除的时候就不需要额外判断链表的头部和尾部,简化了实现。
hashmap则使用Python的dict
1 | class Node: |
参考
- 深入理解计算机系统
- https://en.wikipedia.org/wiki/Cache_replacement_policies
- https://github.com/python/cpython/blob/7247f6f433846c6e37308a550e8e5eb6be379856/Lib/functools.py#L525
- https://zhuanlan.zhihu.com/p/76553221
- https://melonshell.github.io/2020/02/07/ds_cache_eli/
- https://segmentfault.com/a/1190000018810255