一致性哈希是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位(slots)数的改变平均只需要对 K/n 个key需要重新映射,其中K是key的数量,n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
谈到一致性哈希(Consistent hashing),就得先讲一下分布式存储。
比如我们有2000w条数据,一台机器存不下,那么我们可以把分成10份每份200w条存到10台机器上。
这样存储就不成问题,但是查询效率很低,查一条数据要每台机器都查一遍。
如果这些数据能够分类,每一类存到一台机器上,查询前先知道数据的类别,就可以直接定位到某台机器,效率就高了。
原理
那么就得找到一个通用而且均匀的分类方法,可以想到先哈希再取模hash(data) % N
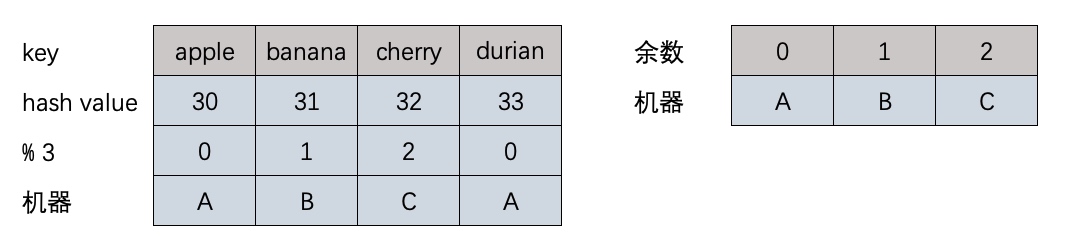
现有这几个数据apple, banana, cherry,durian,希望存储到有3台机器的服务.
1
2
3
4
|
hash("apple") % 3 == 30 % 3 == 0
hash("banada") % 3 == 31 % 3 == 1
hash("cherry") % 3 == 32 % 3 == 2
|
![]()
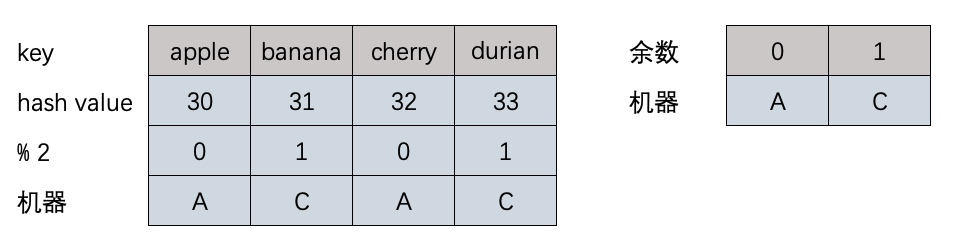
如果B机器宕机了,需要将取模余数和机器重新映射,这时发现3/4的数据都需要迁移
![]()
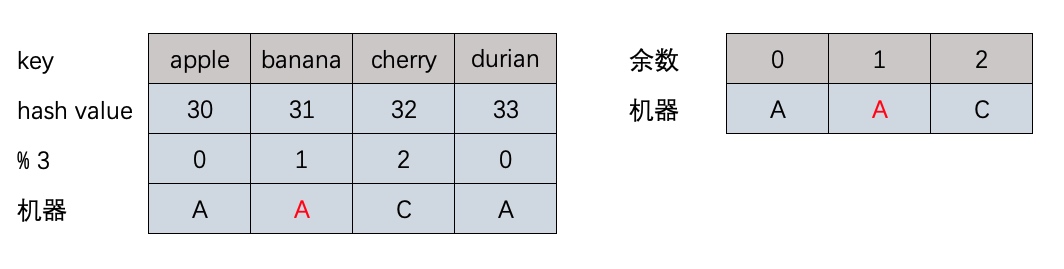
其实当B机器宕机时,取模的除数可以不改成2,依然是hash(data) % 3,这样余数就不会变,只需要把余数和机器的映射改一下,将原先B机器的映射到A机器上,这样只需要迁移1/4的数据.
![]()
但是现在取模的除数和机器数目相等,只能应对机器减少的情况,增加机器就没法处理了。
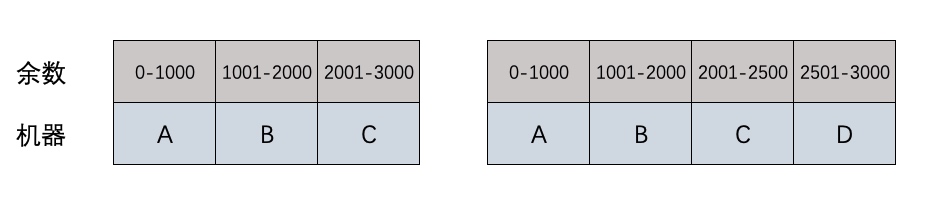
这时可以用一个比较大的数作为除数(比如3000),把除数在一定范围内的都映射到某台机器,增加机器只需要调整余数和机器的映射就行了。
![]()
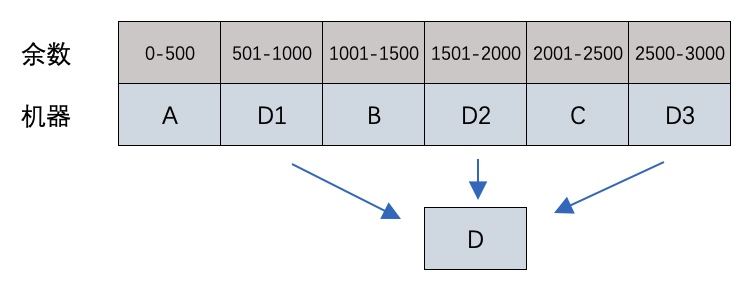
到这里一致性哈希的基本原理已经介绍完了,但对于新增服务器的情况还存在一些问题。
新增的服务器D只分担了C服务器的负载,服务器 A 和 B 并没有因为 D 服务器的加入而减少负载压力。
针对这个问题,可以把D当做多台机器,均匀地放置,这样所有机器的负载都得到分担,也就是所谓的引入虚拟节点。
![]()
实现
下面用Python来实现一致性哈希,这里实现不带虚拟节点的版本。
代码实现和上文分析,有几点细节有些不同
- 简化实现,使用
hashlib.sha1作为哈希函数
- 取模的除数设置为
2^32 - 1,这是C语言中unsiged int的最大取值。
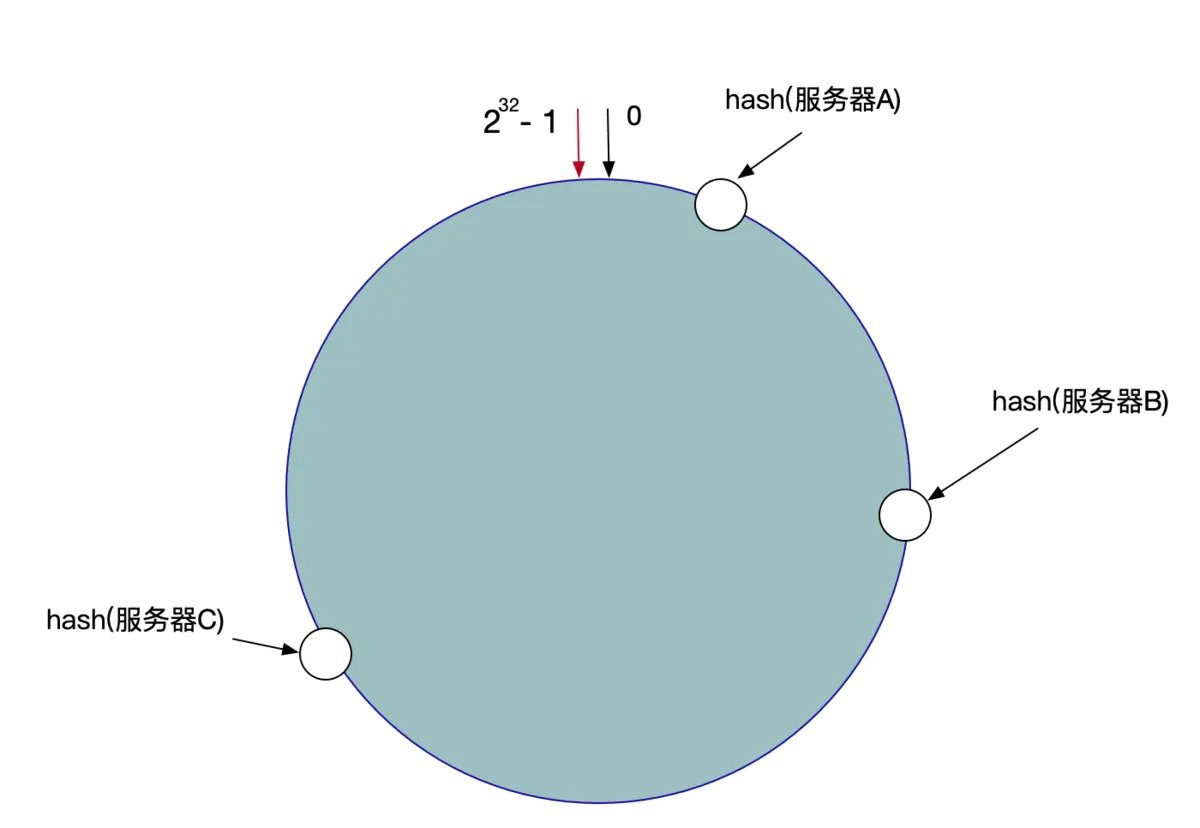
- 根据我们的除数,余数的取值空间就是[0, 2^32 - 1], 可以看成一个首位相连的环。
- 余数和机器的映射不需要单独维护,只要将机器也哈希和取模,就得到机器在环上的位置。
- 机器分布在环上,将余数的取值范围分割成多个区间,每个区间对应一台机器,每台机器负责上一个机器位置到当前机器位置的数据。
![]()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| import hashlib
MASK = 2 ** 32 - 1
def myhash(string):
return int(hashlib.sha1(string.encode("utf-8")).hexdigest(), 16)
def get_pos(obj):
return myhash(obj) % MASK
class Server:
def __init__(self, addr):
self.addr = addr
self.pos = get_pos(self.addr)
def __hash__(self):
return myhash(self.addr)
def __repr__(self):
return '<Server {}; {:,}>'.format(self.addr, self.pos)
class ConsistentHashing:
def __init__(self):
self.servers = []
def add_server(self, server):
assert server not in self.servers
self.servers.append(server)
self.servers.sort(key=lambda i: i.pos)
def get_server(self, key):
assert len(self.servers) > 0
pos = get_pos(key)
for i in self.servers:
if i.pos >= pos:
return i
return self.servers[0]
if __name__ == '__main__':
ch = ConsistentHashing()
ch.add_server(Server('192.168.1.1:80'))
ch.add_server(Server('192.168.1.2:80'))
ch.add_server(Server('192.168.1.3:80'))
print(ch.servers)
print('{:,}'.format(get_pos('123')), ch.get_server('123'))
print('{:,}'.format(get_pos('xxx')), ch.get_server('xxx'))
print('{:,}'.format(get_pos('1')), ch.get_server('1'))
|
参考