布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器原理
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定,比如在Python中通过dict来实现。
使用dict的方案有个局限,就是没办法应用在大规模数据上。
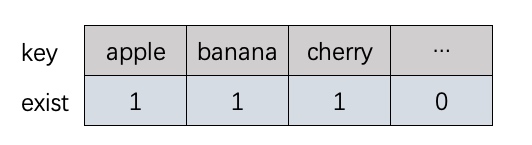
以英语单词为例,我们有三个单词apple,banana,cherry。
如果用dict来存的话是, 查询的准确性是100%,空间占用也是100%
![]()
如果我们对准确性要求降低一些,我们可以只记录单词的首字母;
首字母不存在dict中的话,该单词不存在,否则有可能存在。
![]()
记录首字母的方法虽然有效,但是由于同首字母的单词很多,只记录首字母准确率太低了。
所以我们可以依次记录前2个字母,只有这两个字母都存在,我们才认为该单词存在。
![]()
以此类推,为了提高准确率,我们可以从前2个字母增加到前n个字母。
但是也不能太大,太大的话,dict里的每个字母被重复设置的次数过多,准确率反而会下降。
以上方案还有一个问题,单词中每个字母的分布是很不均匀的,导致准确率对不同的单词也不稳定。
可以不直接记录字母,而是对单词应用哈希函数,并将结果按一个数值(比如26)取模,如hash('apple') % 26,当做一个单词的一个字母来记录。
同时应用多个不同的哈希函数,并记录取模后的值,相当于记录该单词的多个字母。
Python实现
根据上文的分析,可以实现Python版本的布隆过滤器。
用bitmap代替dict,节省空间占用。
使用Python内置的hash函数作为哈希函数。
哈希前对元素增加不同的后缀再调用,替代理论里的多个不同哈希函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| BIT_SIZE = 5000000
BYTE_WIDTH = 8
class BitMap:
def __init__(self, size, fill=0):
self._array = bytearray((fill for _ in range(size//BYTE_WIDTH+1)))
def set(self, index):
major, minor = divmod(index, BYTE_WIDTH)
self._array[major] |= (0b10000000 >> minor)
def get(self, index):
major, minor = divmod(index, BYTE_WIDTH)
mask = 0b10000000 >> minor
return int(self._array[major] & mask == mask)
class BloomFilter:
def __init__(self):
self.bit_array = BitMap(BIT_SIZE)
def add(self, url):
point_list = self.get_postions(url)
for b in point_list:
self.bit_array.set(b)
def contains(self, url):
point_list = self.get_postions(url)
return all(self.bit_array.get(i) for i in point_list)
def get_postions(self, url):
return [hash('{}-{}'.format(url, i)) % BIT_SIZE for i in range(41, 48)]
if __name__ == '__main__':
bf = BloomFilter()
bf.add('1')
print(bf.contains('1'))
print(bf.contains('2'))
|
参考