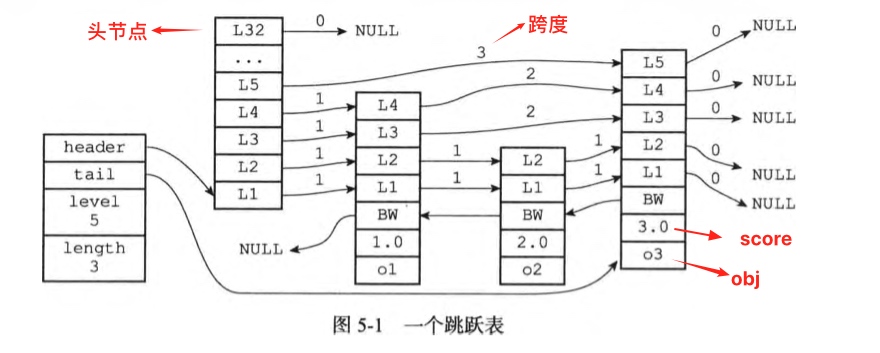
跳跃表 (skiplist) 是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的 指针,从而达到快速访问节点的目的。
跳跃表优点
表支持平均O(logN), 最坏O(N)复杂度的节点查找,效率可以和平衡树相当
通过顺序性操作来批量处理节点
实现比平衡树要来得更为简单
因为ziplist内存占用较小,所以Redis使用作为有序集合的初始底层结构。zset-max-ziplist-entries),又或者有序集合中元素的成员是比较长的字符串时(大于zset-max-ziplist-value),Redis就会将其底层结构转换为跳跃表。
zskiplist 数据结构 跳跃表节点, 其中zskiplistLevel成员是柔性数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 typedef struct zskiplistNode { robj *obj; double score; struct zskiplistNode *backward ; struct zskiplistLevel { struct zskiplistNode *forward ; unsigned int span; } level[]; } zskiplistNode;
跳跃表
1 2 3 4 5 6 7 8 typedef struct zskiplist { struct zskiplistNode *header , *tail ; unsigned long length; int level; } zskiplist;
所谓跳跃表,就是多层链表(redis中的实现是最多32层)通过额外的链接提高效率,从低层到高层,节点之间的跨度逐渐变大。
跨度越大则查找效率越高,所以查找时是从高层往底层查找。
如果节点的最高层高为x,则可以认为该节点就存储在低x层,则表头到该节点的跨度之和为该节点的rank(排位),所有节点的最大层高为跳跃表层高。
跳跃表插入节点 因为跳跃表是多层链表,所以插入节点的关键是找到每一层插入的位置,以及插入位置的跨度变化,还有新节点的跨度计算。
python 版跳跃表插入实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 def _node_lt (node: zskiplistNode, score: float , obj: robj ): if node.score < score: return True if (node.score == score and compareStringObjects(node.obj, obj) < 0 ): return True return False def zslInsert (zsl: zskiplist, score: float , obj: robj ) -> zskiplistNode: update: List [Opt[zskiplistNode]] = [None for _ in range (ZSKIPLIST_MAXLEVEL)] rank = [0 for _ in range (ZSKIPLIST_MAXLEVEL)] x = zsl.header for i in range (zsl.level-1 , -1 , -1 ): rank[i] = 0 if i == zsl.level-1 else rank[i+1 ] while x.level[i].forward and _node_lt(x.level[i].forward, score, obj): rank[i] += x.level[i].span x = x.level[i].forward update[i] = x level = zslRandomLevel() if level > zsl.level: for i in range (zsl.level, level): rank[i] = 0 update[i] = zsl.header update[i].level[i].span = zsl.length zsl.level = level x = zslCreateNode(level, score, obj) for i in range (level): x.level[i].forward = update[i].level[i].forward update[i].level[i].forward = x x.level[i].span = update[i].level[i].span - (rank[0 ] - rank[i]) update[i].level[i].span = (rank[0 ] - rank[i]) + 1 for i in range (level, zsl.level): update[i].level[i].span += 1 x.backward = None if update[0 ] == zsl.header else update[0 ] if x.level[0 ].forward: x.level[0 ].forward.backward = x else : zsl.tail = x zsl.length += 1 return x
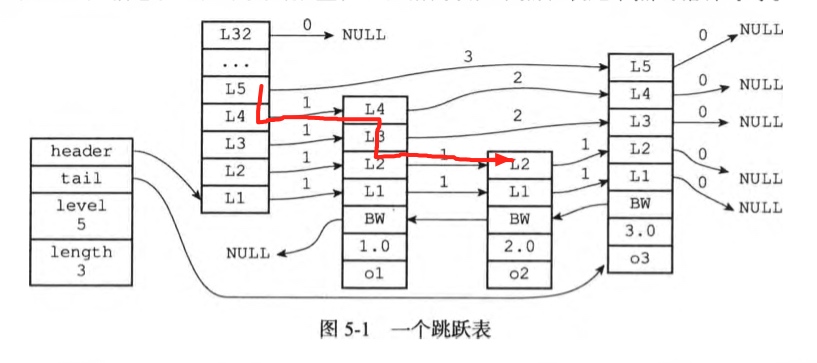
跳跃表查找 跳跃表的查找则是从高层向低层查找,沿着最高层链表前进;遇到大于目标值的节点,则往下一层,直到找到相等的值为止。
经过的所有节点的跨度相加即是目标节点的rank。
1 2 3 4 5 6 7 8 9 10 def zslGetRank (zsl: zskiplist, score: float , obj: robj ) -> int : rank = 0 x = zsl.header for i in range (zsl.level-1 , -1 , -1 ): while x.level[i].forward and _node_lt(x.level[i].forward, score, obj): rank += x.level[i].span x = x.level[i].forward if x.obj and equalStringObjects(x.obj, obj): return rank return 0
查找score=2.0的o2对象的过程
参考