Redis原理 —— dict 字典
这是Redis源码阅读系列第一篇文章。
dict 是 redis 最重要的数据结构,db、hash、以及服务器内部需要用到hashmap的场景都是用dict来实现的。学习 dict 的源码,我们可以学到hashmap的原理及实现。
dict 数据结构
哈希表元素节点
1 | typedef struct dictEntry { |
哈希表
1 | typedef struct dictht { |
字典
1 | typedef struct dict { |
结构体,储存不同类型字典的操作函数指针,实现了多态
1 | typedef struct dictType { |
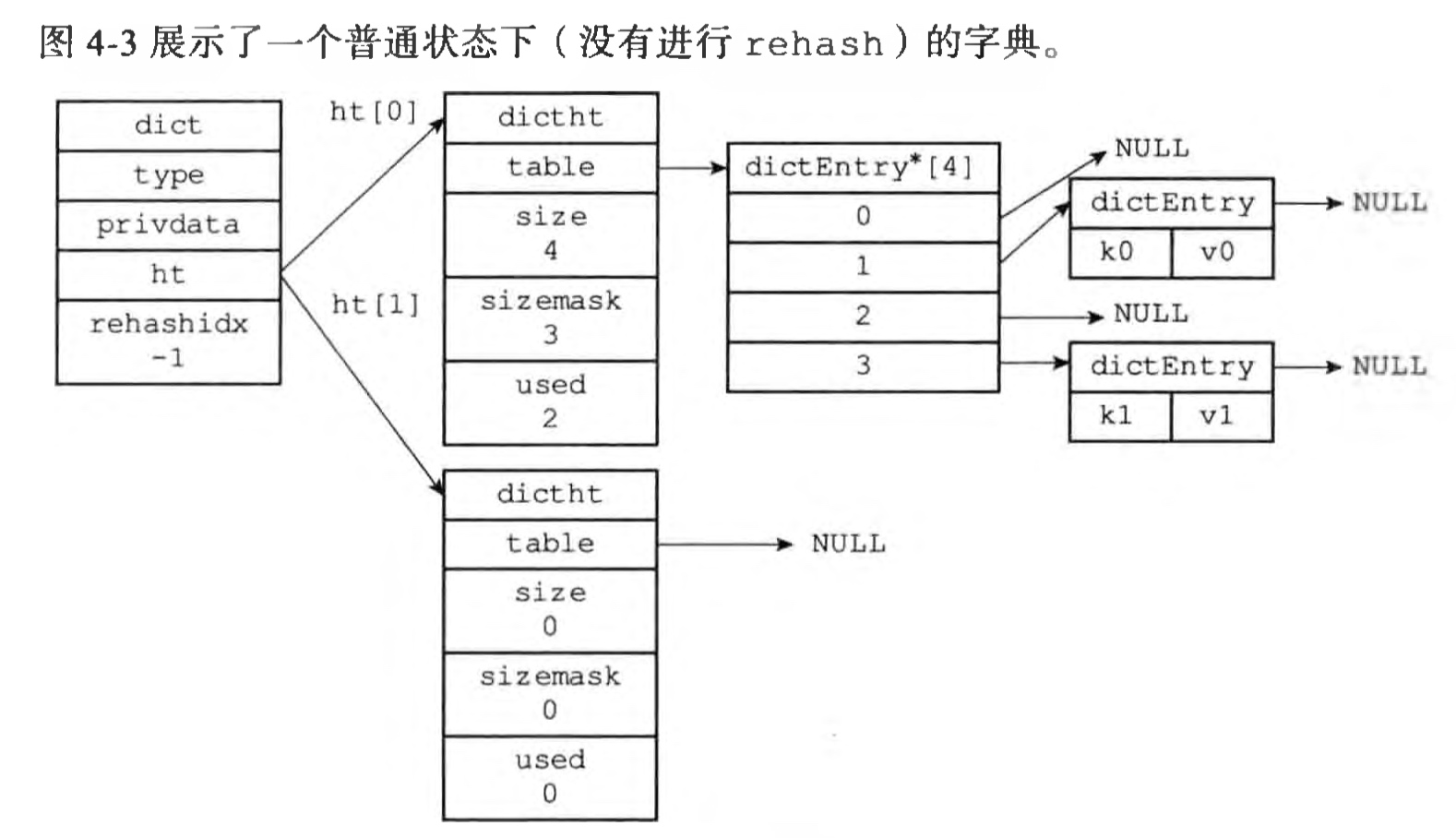
哈希算法
redis 的 dict 本质上就是个hashmap,其中的关键是哈希算法。
哈希函数(英语:Hash function)又称散列算法、散列函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值的指纹。
比如取模函数就是一种最简单的对整数的哈希算法。
当字典被用作数据库的底层实现,或者哈希键的底层实现时,Redis使用 MurmurHash2 算法来计算键的哈希值。
具体求索引的过程
1 | // 求哈希值 |
冲突解决
当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时,我们称这些键发生了冲突。
常见冲突解决方法
链地址法:用链表储存冲突项
开放地址法:按照一定顺序寻找下一个可用位置(x为当前位置)
- 线性探测法:按顺序向后查找,x+1, x+2, x+3
- 平方探测法:平方向后查找,x+1,x+4,x+9
- 双散列法
再哈希法:依次使用多个哈希函数
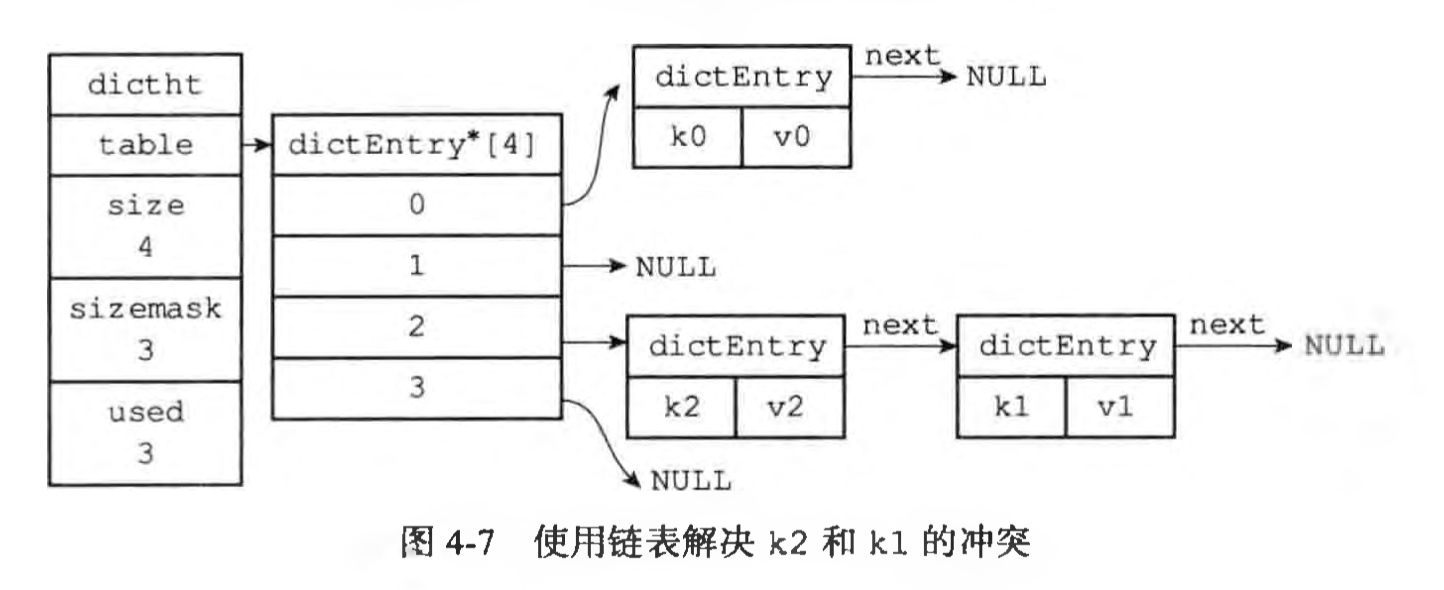
Redis的哈希表使用链地址法(separate chaining) 来解决键冲突,每个哈希表节点都有一个next指针,多个哈希表节点可以用 next指针构成一个单向链表,被分配到同一个索 引上的多个节点可以用这个单向链表连接起来,这就解决了键冲突的问题。
还有一种常用的冲突解决办法是再哈希法,就是同时构造多个不同的哈希函数。
当H1 = hashfunc1(key) 发生冲突时,再用H2 = hashfunc1(key) 进行计算,直到冲突不再产生,这种方法不易产生聚集,但是增加了计算时间。
rehash
随着操作的不断执行,哈希表保存的键值对会逐渐地增多或者减少,为了让哈希表的负载因子(used/size)维持在一个合理的范围之内,程序需要对哈希表的大小进行相应的扩展或者收缩, 这个过程就是rehash。
这里redis采用的装载系数为1,扩容系数为2
Redis对字典的哈希表执行rehash的步骤如下:
- 为字典的
ht[1]哈希表分配空间 - 将保存在
ht[0]中的所有键值对rehash到ht[1]上面:rehash指的是重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上 - 全部复制完成后,释放
ht[0],将ht[1]设置为ht[0],重置ht[1]
渐进式 rehash
所谓渐进式,是指rehash动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。
由于redis是单线程的, 哈希表里保存的键值对又可能非常多,一次性将这些键值对全部rehash到ht[1],会导致服务器在一段时间内停止服务。
所以需要渐进式 rehash,在字典的每个添加、删除 、查找和更新操作的时候,顺便进行部分元素的 rehash(目前实现是rehash一个元素),避免了集中式rehash而带来的庞大计算量。
rehash 示例代码
1 | def dictRehash(d: rDict, n: int) -> int: |
除了渐进式rehash,对于redis的多个db,也会有定时任务进行主动rehash,防止服务器长期没有执行命令时,数据库字典的 rehash 一直没办法完成。
参考
- redis 3.0 源码
- redis 设计与实现