Python日志原理及实践
原理
一次简单的日志记录
1 | import logging |
output
1 | warning division by zero |
logging.getLogger获取一个记录器, 一般以模块名称命名- 调用日志记录器的相应方法记录日志
记录器 (logger)
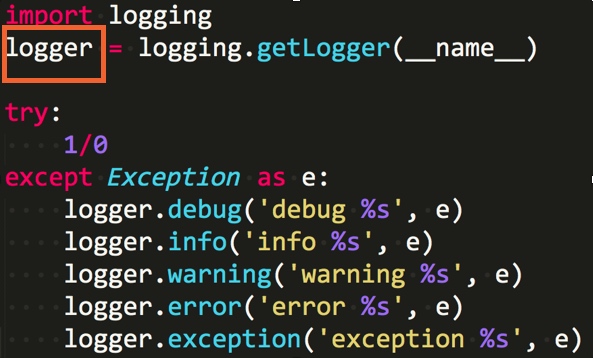
- logger是Python记录日志的入口
- logger.info, logger.debug等几个函数对应记录不同的日志级别
- 日志配置可以设置日志级别, 低于日志级别的日志不被记录
- 默认日志配置的级别是WARNING
Python日志支持的级别
| 级别 | 何时使用 |
|---|---|
| DEBUG | 详细信息,典型地调试问题时会感兴趣。 |
| INFO | 证明事情按预期工作。 |
| WARNING | 表明发生了一些意外,或者不久的将来会发生问题软件还是在正常工作。 |
| ERROR | 由于更严重的问题,软件已不能执行一些功能了。 |
| CRITICAL | 严重错误,表明软件已不能继续运行了。 |
记录 (record)
每个record对象代表一条日志
record拥很多有的属性, 可扩展, 主要被formatter使用
日志记录器的记录方法每次被调用就会生成一条record对象, 并且将record的所有属性都设置好.
record主要有以下属性
| name | logger名称 |
|---|---|
| msg | 日志文本 |
| args | 格式文本的参数 |
| levelname | 级别名称 |
| module | 模块名称 |
| exc_info | 异常相关信息 |
| lineno | 行号 |
| funcName | 打日志的函数名称 |
| threadName | 线程名 |
| processName | 进程名称 |
处理器 (handler)
日志处理器决定了日志的存储的方式, 存储大小,存储的位置
日志处理器通过handle方法处理日志, 不同的处理器行为差别很大
一些常见的日志处理器
- StreamHandler 输出到终端
- SMTPHandler 通过 email 发送日志记录
- SocketHandler 将日志通过网络发送
- FileHandler 记录到文件
- TimedRotatingFileHandler 记录到文件并按时间滚动
过滤器 (filter)
filter是附加在logger上的, 对日志进行细粒度控制, 例如根据一些条件判断是否记录日志, 修改日志record的内容等
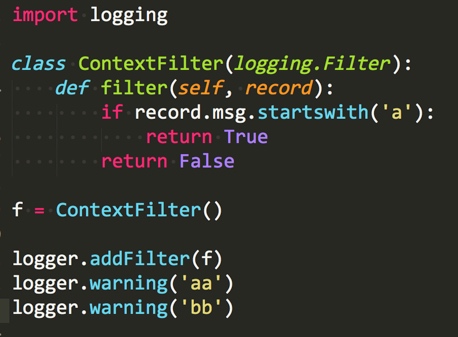
例如上面这个ContextFilter, 就将第二条日志过滤掉了.
格式器 (formatter)
根据配置,将日志record的属性格式化成字符串

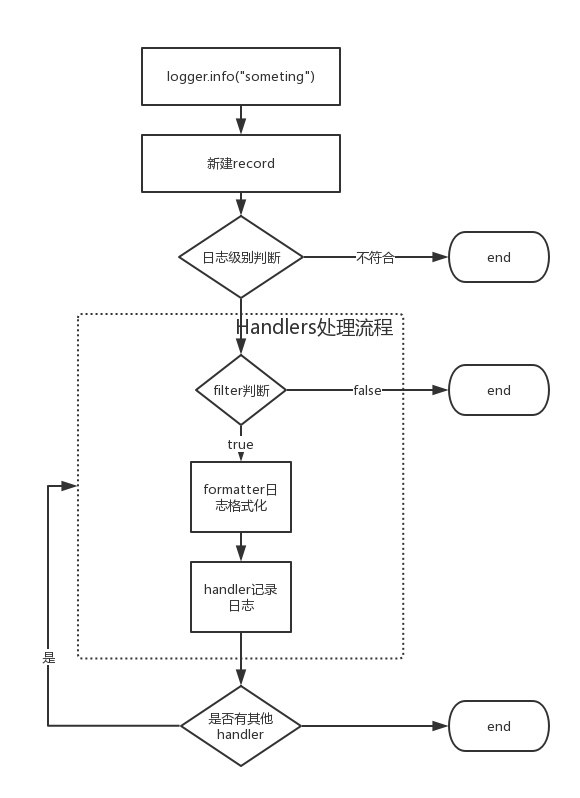
日志处理流程
解释完这些名词, 然后看这个这个流程图, 就会明白整个日志的处理流程
日志配置
开发过程中觉得比较好的一个日志配置
1 | LOGGING = { |
最佳实践
要打哪些日志
问题定位
- web请求入口和出口
- 外部服务调用入参和返回
- 未预料的程序异常
- 关键流程记录
- 启动、关闭、配置加载
性能分析
- 函数\服务调用耗时记录
每条日志要包含哪些内容
基本信息
1
2
3'%(levelname)s %(asctime)s %(name)s %(funcName)s %(lineno)d %(process)d %(thread)d %(message)s'
日志级别 时间 logger名称 函数名称 函数名 行号 进程id 线程id唯一请求id
必要的描述信息: 如request xxx failed
异常相关信息, 调用trace info
日志级别
正确地使用日志级别, 不要乱用级别
ERROR:该级别的错误也需要马上被处理。当ERROR错误发生时,已经影响了用户的正常访问,是需要马上得到人工介入并处理的。
WARNING:该日志表示系统可能出现问题,也可能没有,这种情况如网络的波动等。对于WARN级别的日志,虽然不需要系统管理员马上处理,也是需要及时查看并处理的。因此此种级别的日志也不应太多,能不打WARNING级别的日志,就尽量不要打;
INFO:该种日志记录系统的正常运行状态, 占日志的大部分;
DEBUG:开发过程中的调试信息。
日志存储
文件
- 日志滚动: 按时间或按大小滚动. 同时配置最大保存的数目
- 存储路径: 放到空间比较大目录
- 注意是否多进程写日志
- error级别日志输出到单独文件
网络日志
- 单机情况下一般不需要
- 多机部署可用kafka,ELK等方案
一些记录的建议
- 不要使用print代替日志
- 日志对程序性能有影响, 不要打很多没有必要的日志.
- 不同的日志handler有不同的适用场景, 要选择合适的handler
- Python内置的所有handler只是线程安全, 多进程场景可以打日志到多个文件, 或者使用网络日志