Docker mtu 引发的加班血案
最近在搞 torch 的工程化,基于 brpc 和 libtorch,将两者编译在一起的过程也是坑深,容下次再表。
为了简化部署,brpc 服务在 Docker 容器中运行。本地测试时功能一切正常,上到预发布环境时请求全部超时。
由于业务代码,brpc,docker环境,机房都是新的,在排查问题的过程中简直一头雾水。(当然根本原因还是水平不足)
使尽浑身解数定位
发现请求超时后,开始用CURL测试接口,用真实数据验证发现请求都耗时1s,这和用c++的预期完全不符。
我代码不应该有bug!!
首先是怀疑业务代码有问题,逐行统计业务代码耗时,发现业务代码仅耗时10+ms。
curl 不应该 Expect
用空数据访问接口,发现耗时也只有20+ms,这时开始怀疑brpc是不是编译得有问题,或者说和libtorch编译到一起不兼容。
这时我请教了一位同事,他对brpc比较熟悉,然后他说是curl实现的问题,和brpc没关系, 参考 brpc issue
1 | curl传输的时候,会设置 Expect: 100-continue, 这个协议brpc本身没有实现, 所以curl会等待一个超时。 |
所以这个1s超时是个烟雾弹,线上client是Python,不会有这个问题。
难道是 lvs ?
接着又是一通疯狂测试,各种角度体位测试。发现本机测试是ok的,透过lvs请求(跨机房)就会卡住直到超时,而且小body请求一切正常,大body请求卡住。
这时又开始怀疑brpc编译的不对,导致这个超时(brpc编译过程比较曲折,导致我不太有信心)。
于是我在这个服务器Docker中运行了另一个brpc服务,发现是一样的问题。
为了确认是否是brpc的问题,又写了个Python 的 echo server 进行测试,发现在docker中是一样的问题,但是不在docker中运行有一切正常。
这是时就可以确定,与代码无关,是docker或者lvs的问题,一度陷入僵局。
docker 才是罪魁祸首
完全没思路,于是找来了运维的同学,这时运维提了一下,这个机房的mtu会小一点,于是一切串起来了。
马上测试,发现机房的mtu只有1450,而docker0网桥的默认mtu是1500,这就很能解释小body没问题,大body卡死。
1 | ~# netstat -i |
修改docker0的mtu,重启docker.service,一切问题都解决了。
1 | cat << EOF > /etc/docker/daemon.json |
事后诸葛
找到问题等于解决了一半
这句话说得并不太懂,应该是“找到问题等于解决了90%”。
在互联网时代,找到了具体问题,在一通Google,基本等于解决了问题。你始终要确信,这个问题不应该只有你遇到。
在这个例子上,curl的误导大概花了一半的时间去定位。所以,定位问题首先得明确问题,如医生看病一样,确认问题发生的现象(卡住),位置(docker容器中)、程度(永久)、触发原因(大请求body)。
要善于运用他人的经验和知识
找专业人士寻求帮助是非常高效的,会大大缩短定位问题的时间,因为他们会运用经验和知识快速排除错误选项。
知识可能会误导你
你所拥有的知识,并不是究竟的知识,也就是它所能应用的范围并不适应当前的场景,还有可能误导你。
你所缺失的知识,让你看不清前方正确的道路。
按我的知识,docker0是网桥,等价于交换机,除了性能问题,不应该导致丢包,就一直没往这个方向考虑(当然这块的知识也不扎实)。
MTU也不应该导致丢包,交换机应该会进行IP分片。
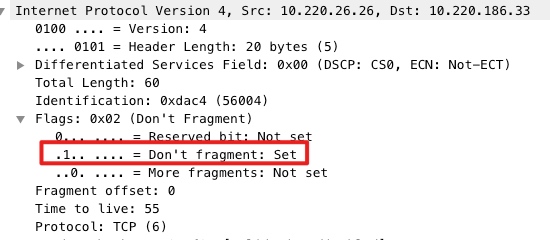
但忽略了一个点,虚拟的网桥并不是硬件网桥,可能并没有实现IP分片的逻辑(仅丢弃),又或者没有实现 PMTU(Path MTU Discovery)。
上面这点存疑,但更直接的原因是服务的IP包的 Don't fragment flag 为1,也就是禁止分片(为什么设置还不清楚)。