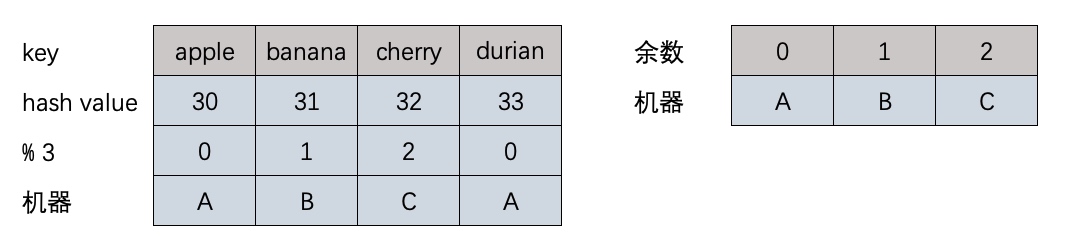
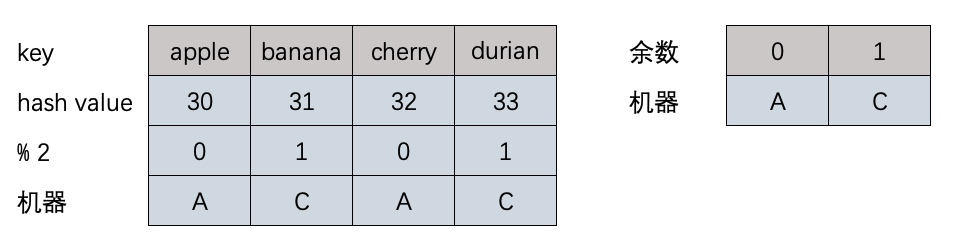
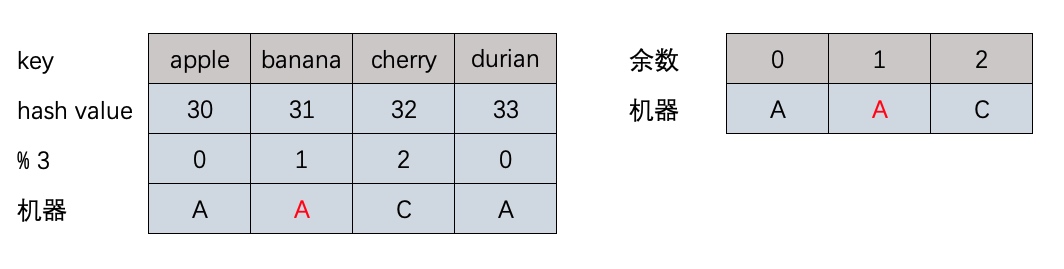
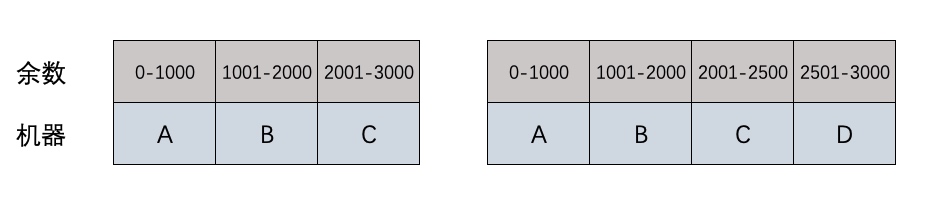
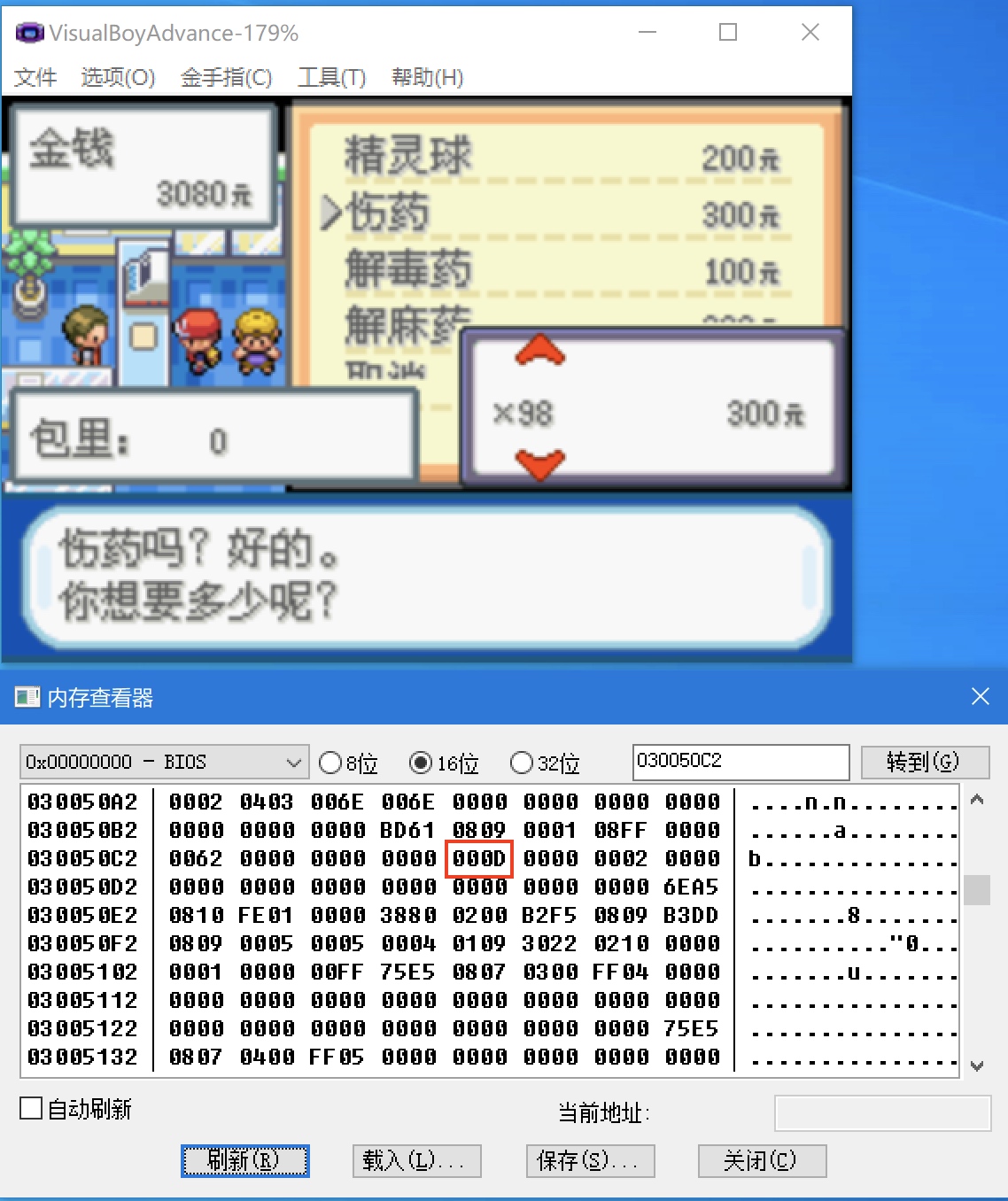
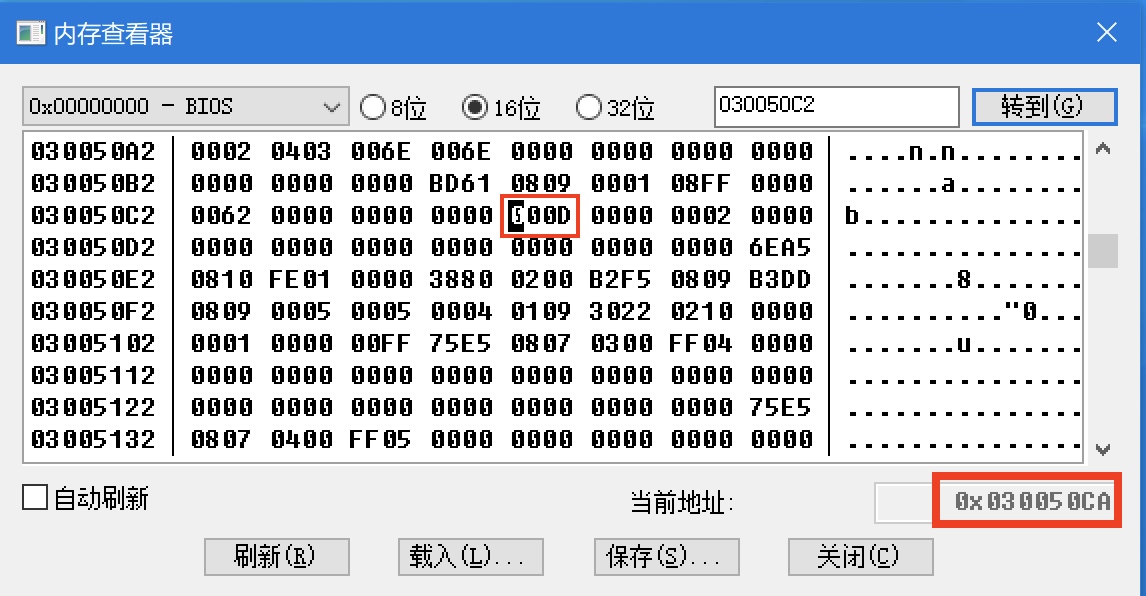
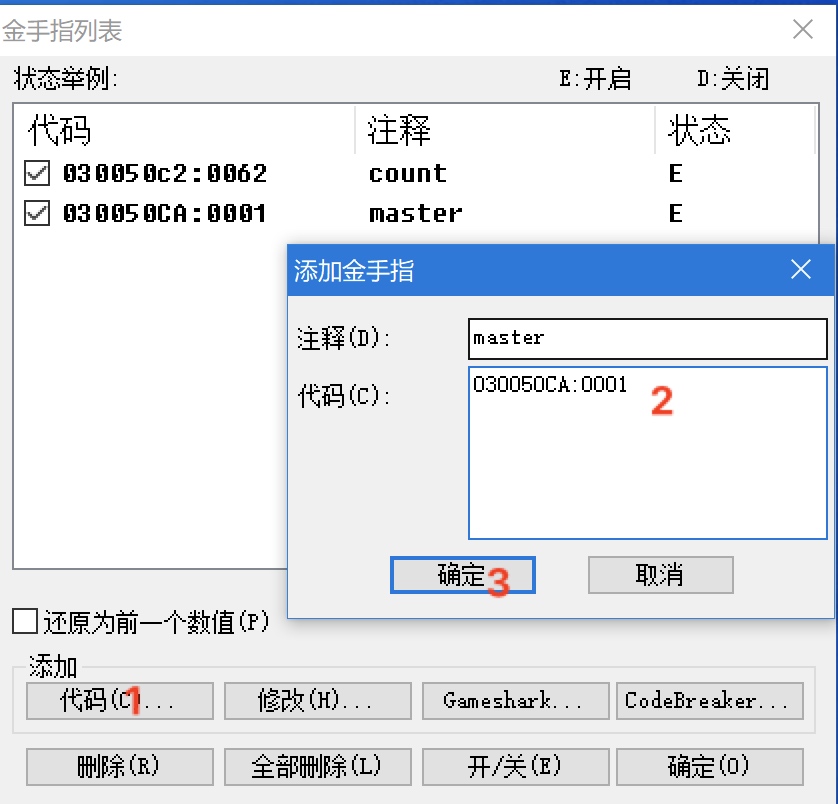
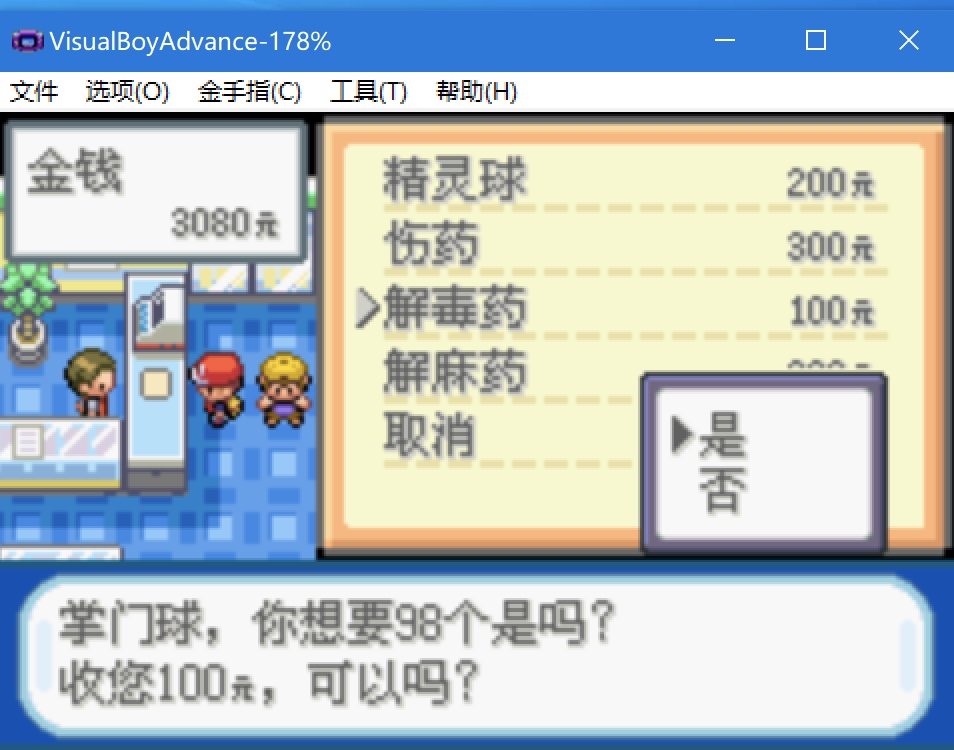
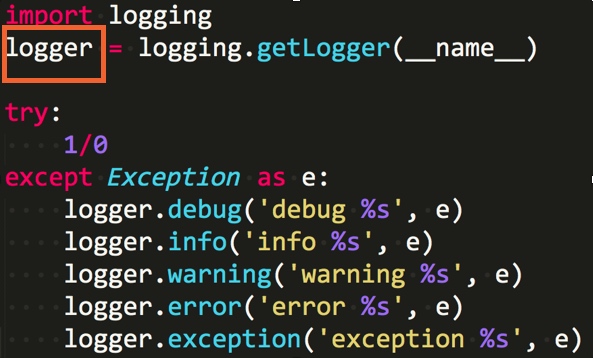
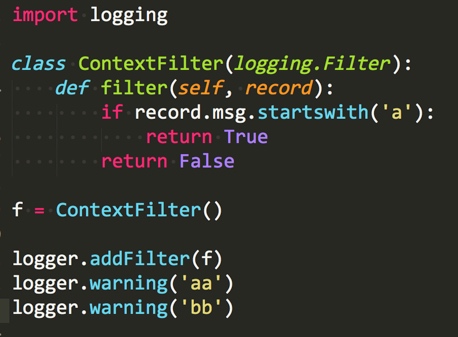
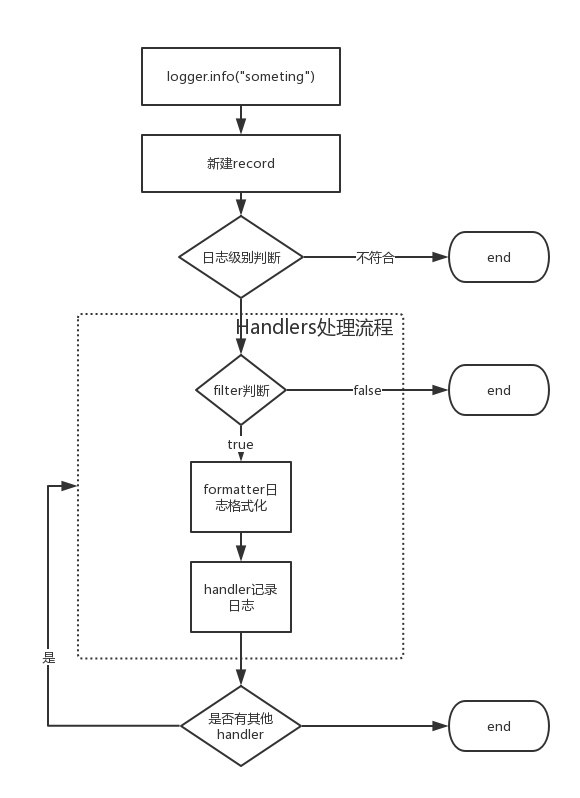
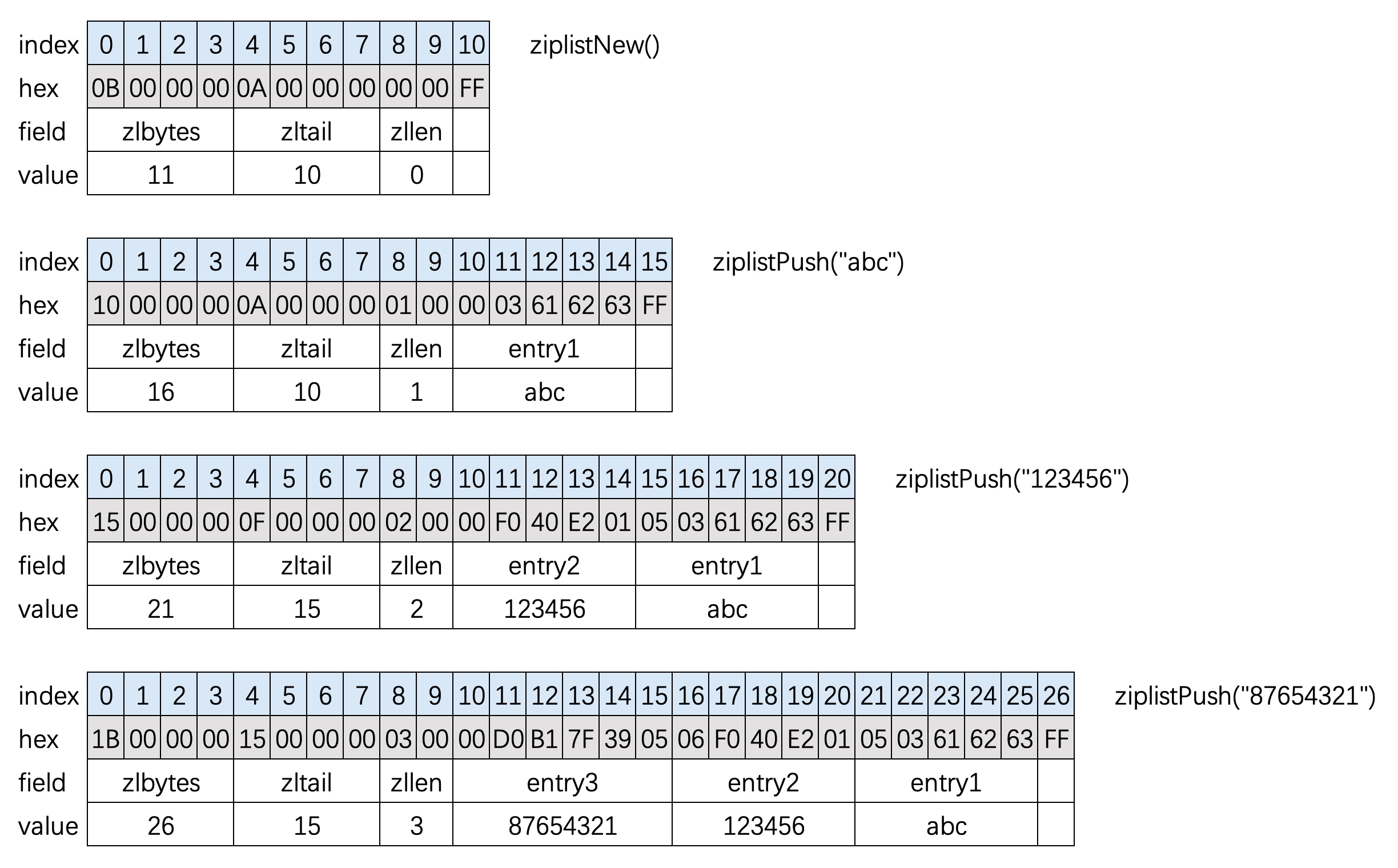
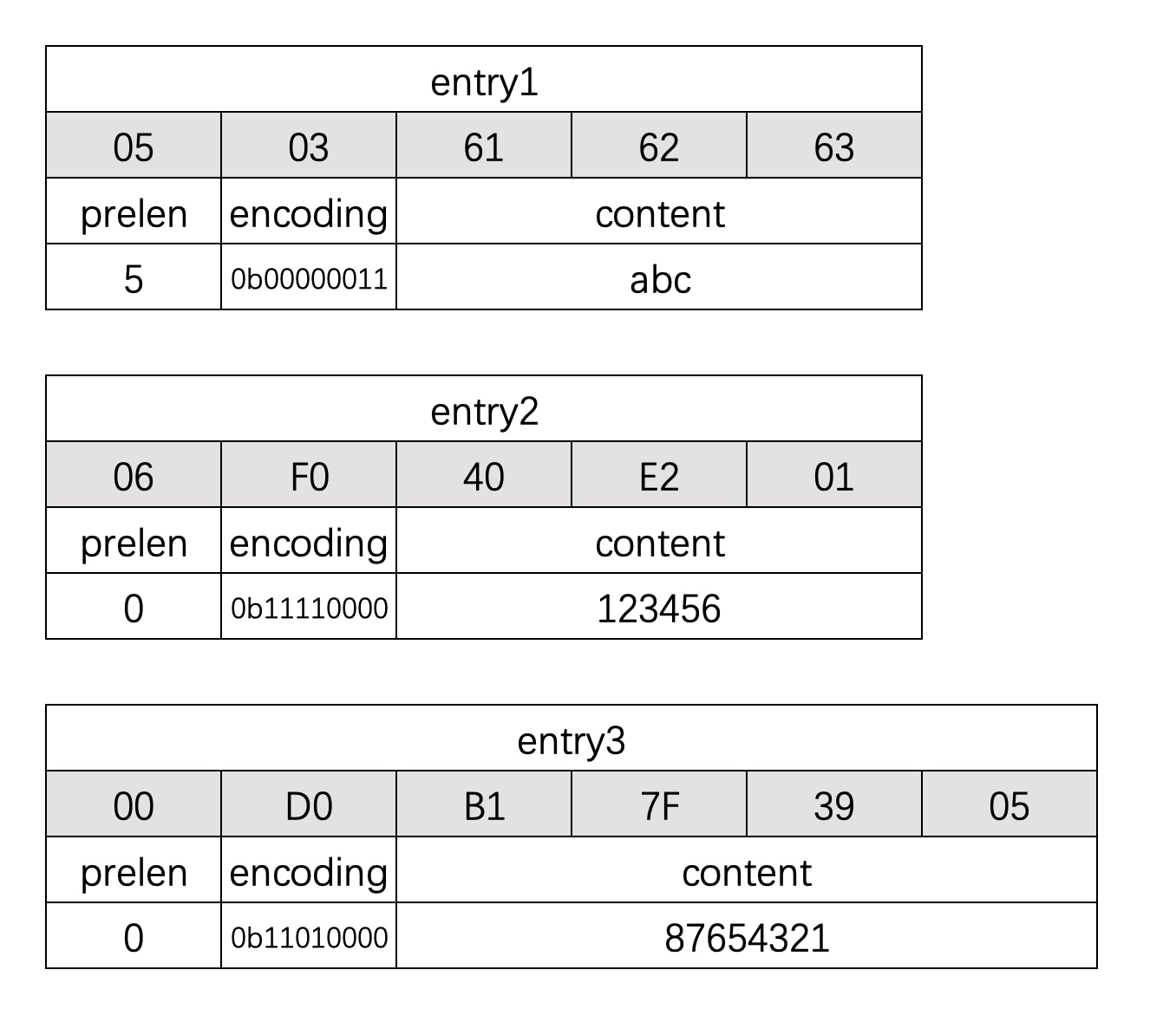
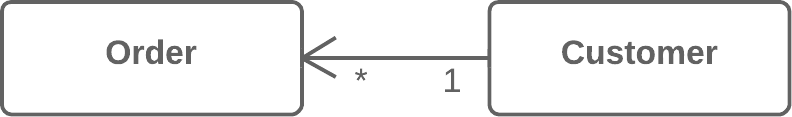defaa(): now = time.time() string = 'sfsfdsdffffffffffsxcsdsffffffsdsfsffssadfsaasfffffsdssfssssdsdcvfgbdgssdfvdfsss' for i in xrange(5000000): re.match(r'f(s)', string) seconds = time.time() -now return seconds
defbb(): now = time.time() string = 'sfsfdsdffffffffffsxcsdsffffffsdsfsffssadfsaasfffffsdssfssssdsdcvfgbdgssdfvdfsss' pp = re.compile(r'f(s)') for i in xrange(5000000): re.match(pp, string) seconds = time.time() -now return seconds
defcc(): now = time.time() string = 'sfsfdsdffffffffffsxcsdsffffffsdsfsffssadfsaasfffffsdssfssssdsdcvfgbdgssdfvdfsss' pp = re.compile(r'f(s)') for i in xrange(5000000): pp.match(string) seconds = time.time() -now return seconds
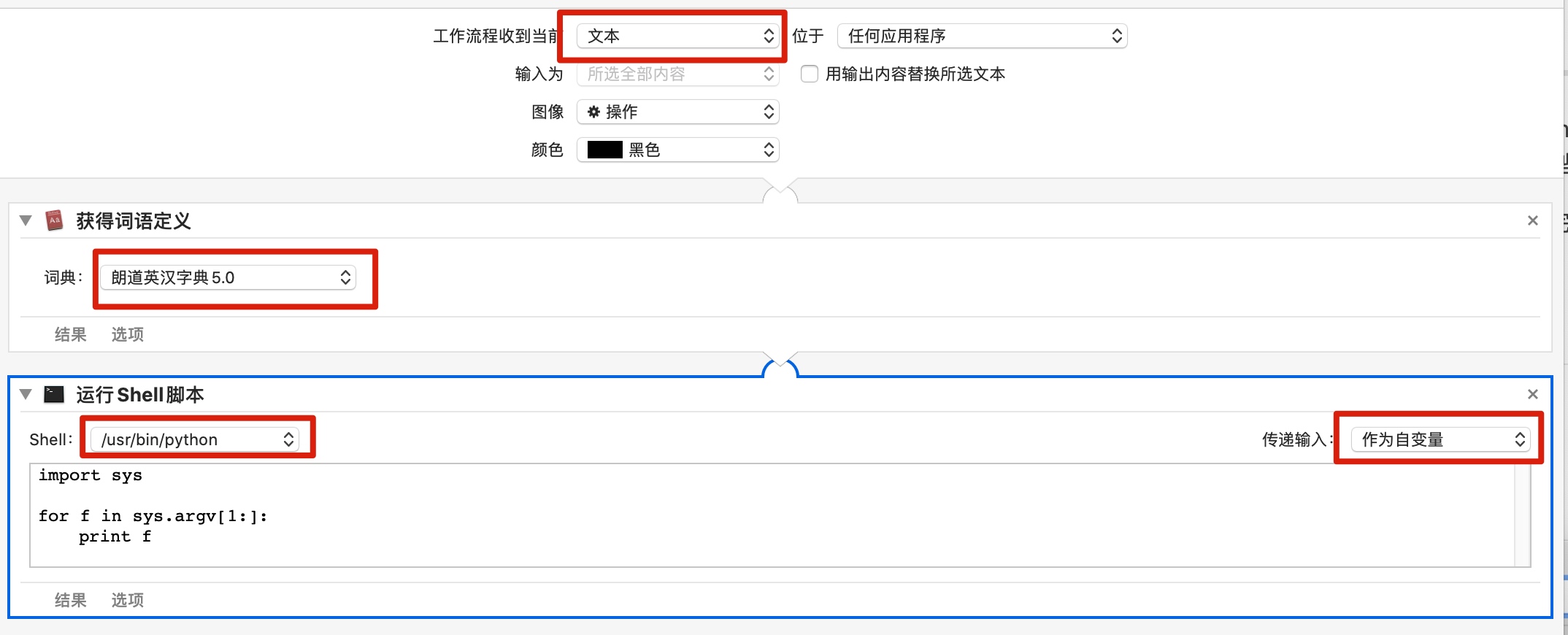
from __future__ import unicode_literals, print_function import sys, os, io, subprocess
FILE=os.path.expanduser("~/weiyun_sync/!sync/logseq-note/pages/生词本.md") output = [] text = sys.argv[1].decode('utf8') if sys.version_info.major == 2else sys.argv[1]
lines = [i.strip() for i in text.splitlines() if i.strip()] if len(lines) < 2: exit(0)
word = lines[0] if lines[1][0] == '*': output.append('- {}\t{} [[card]]'.format(word, lines[1])) lines = lines[2:] else: output.append('- {}\t [[card]]'.format(word)) lines = lines[1:] output.append('\t- {}'.format(lines[0])) for line in lines[1:]: output.append('\t ' + line)
old_words = set() with io.open(FILE, 'r', encoding='utf8') as fp: for line in fp: parts = line.split() if line.startswith('-') and len(parts) > 1: old_words.add(parts[1])
if word notin old_words: with io.open(FILE, 'a', encoding='utf8') as fp: fp.write('\n') fp.write('\n'.join(output)) fp.write('\n') subprocess.check_call(['osascript', '-e', u'display notification "添加 {}" with title "生词本"'.format(word)]) else: subprocess.check_call(['osascript', '-e', u'display notification "跳过 {}" with title "生词本"'.format(word)])
#test if test 1 -eq 2 || test 1 -eq 1; then echo True fi
# [ ] if [ 1 -eq 2 ] || [ 1 -eq 1 ]; then echo True fi
# [[ ]] if [[ 1 -eq 2 || 1 -eq 1 ]]; then echo True fi
逻辑操作符
判断条件支持且(&&)或(||)非(!)
# not if [[ ! 'aa' == 'bb' ]]; then echo True fi
# or if [[ 1 -eq 2 || 1 -eq 1 ]]; then echo True fi
# and if [[ 1 -ne 2 && 1 -eq 1 ]]; then echo True fi
判断时引号使用(quote)
使用[和test时,变量引用注意加双引号,否则得不到正确的结果,[[则不需要。
bash-3.2$ echo "$SSH_CLIENT"
bash-3.2$ if [ -n $SSH_CLIENT ]; then echo 1; else echo 0; fi 1 bash-3.2$ if [ -n "$SSH_CLIENT" ]; then echo 1; else echo 0; fi 0 bash-3.2$ if [[ -n $SSH_CLIENT ]]; then echo 1; else echo 0; fi 0
Standard output is empty Traceback (most recent call last): File"<stdin>", line7, in <module> File"/Users/ruan/.pyenv/versions/2.7.16/lib/python2.7/site-packages/sklearn2pmml/__init__.py", line262, in sklearn2pmml print("Standard error:\n{0}".format(_decode(error, java_encoding))) UnicodeEncodeError: 'ascii' codec can't encode character u'\u6708' in position 1: ordinal notinrange(128) 'ascii' codec can't encode character u'\u6708' in position 1: ordinal notinrange(128)
run or r –> executes the program from start to end. break or b –> sets breakpoint on a particular line. disable -> disable a breakpoint. enable –> enable a disabled breakpoint. next or n -> executes next line of code, but don’t dive into functions. step –> go to next instruction, diving into the function. list or l –> displays the code. print or p –> used to display the stored value. quit or q –> exits out of gdb. clear –> to clear all breakpoints. continue –> continue normal execution.
import time deffib(n): time.sleep(0.01) if n == 1or n == 0: return1 for i in range(n): return fib(n-1) + fib(n-2)
fib(100)
启动程序
python3 fib.py &
gdb python3 148, 148为Python的进程id
gdb输出,注意所需要的symbols是否都加载了
GNU gdb (Ubuntu 9.2-0ubuntu1~20.04) 9.2 Copyright (C) 2020 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration" for configuration details. For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>. For help, type "help". Type "apropos word" to search for commands related to "word"... Reading symbols from python3... Reading symbols from /usr/lib/debug/.build-id/02/526282ea6c4d6eec743ad74a1eeefd035346a3.debug... Attaching to program: /usr/bin/python3, process 148 Reading symbols from /lib/x86_64-linux-gnu/libc.so.6... Reading symbols from /usr/lib/debug//lib/x86_64-linux-gnu/libc-2.31.so... Reading symbols from /lib/x86_64-linux-gnu/libpthread.so.0... Reading symbols from /usr/lib/debug/.build-id/4f/c5fc33f4429136a494c640b113d76f610e4abc.debug... [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1". Reading symbols from /lib/x86_64-linux-gnu/libdl.so.2... Reading symbols from /usr/lib/debug//lib/x86_64-linux-gnu/libdl-2.31.so... Reading symbols from /lib/x86_64-linux-gnu/libutil.so.1... Reading symbols from /usr/lib/debug//lib/x86_64-linux-gnu/libutil-2.31.so... Reading symbols from /lib/x86_64-linux-gnu/libm.so.6... Reading symbols from /usr/lib/debug//lib/x86_64-linux-gnu/libm-2.31.so... Reading symbols from /lib/x86_64-linux-gnu/libexpat.so.1... (No debugging symbols found in /lib/x86_64-linux-gnu/libexpat.so.1) Reading symbols from /lib/x86_64-linux-gnu/libz.so.1... (No debugging symbols found in /lib/x86_64-linux-gnu/libz.so.1) Reading symbols from /lib64/ld-linux-x86-64.so.2... (No debugging symbols found in /lib64/ld-linux-x86-64.so.2) 0x00007fec057c10da in __GI___select (nfds=nfds@entry=0, readfds=readfds@entry=0x0, writefds=writefds@entry=0x0, exceptfds=exceptfds@entry=0x0, timeout=timeout@entry=0x7fff99ce33a0) at ../sysdeps/unix/sysv/linux/select.c:41 41 ../sysdeps/unix/sysv/linux/select.c: No such file or directory.
(gdb) py-list 1 import time 2 def fib(n): >3time.sleep(0.01) 4if n == 1or n == 0: 5return1 6for i inrange(n): 7returnfib(n-1) + fib(n-2) 8 (gdb) n 4970in ../Python/ceval.c (gdb) py-locals n = 4 (gdb) b Breakpoint 2at0x56acbe: file ../Include/object.h, line 459. (gdb) c Continuing.
Breakpoint 2, _PyEval_EvalFrameDefault (f=<optimized out>, throwflag=<optimized out>) at ../Include/object.h:459 459in ../Include/object.h ... # 省略一些c命令 (gdb) py-locals n = 3 (gdb) py-bt Traceback (most recent call first): File "fib.py", line 4, infib if n == 1or n == 0: File "fib.py", line 7, infib returnfib(n-1) + fib(n-2) ... 省略一些输出 (gdb) (gdb) py-up #6 Frame 0x7fec0531a580, for file fib.py, line 7, infib (n=4, i=0) returnfib(n-1) + fib(n-2) (gdb) py-locals n = 4 i = 0 (gdb) py-up #18 Frame 0x7fec0531c040, for file fib.py, line 7, infib (n=7, i=0) returnfib(n-1) + fib(n-2) (gdb) py-print i local 'i' = 0 (gdb) py-print n local 'n' = 7 (gdb) py-down #12 Frame 0x7fec0531a900, for file fib.py, line 7, infib (n=6, i=0) returnfib(n-1) + fib(n-2) (gdb) py-print n local 'n' = 6
if len(running_args) == 1and callable(running_args[0]): return decorator(running_args[0]) else: return decorator
@running(system='linux') defhello(who='nobody'): return"hello, %s!" % who
@running defhello2(who='nobody'): return"hello, %s!" % who
print(hello('foo')) print(hello2('bar'))
output
`hello` is running at linux run `hello` takes 2.5033950805664062e-05 seconds hello, foo! `hello2` is running at mac run `hello2` takes 3.814697265625e-06 seconds hello, bar!
OAPI_DOMAIN = 'oapi.dingtalk.com'# dingtalk open api domain
classDingdingApiError(RuntimeError): pass
classDingTalkHandler(logging.Handler): """Handler for logging message to dingtalk""" pass # 略去逻辑代码
编写 setup.py
setup.py指引了打包工具如何打包我们的库,功能与类似Makefile
from setuptools import setup, find_packages from dingtalk_log_handler import __author__, __version__
# read the contents of your README file from os import path this_directory = path.abspath(path.dirname(__file__)) with open(path.join(this_directory, 'README.md'), encoding='utf-8') as f: long_description = f.read()
setup( name='dingtalk-log-handler', version=__version__, author=__author__, author_email='xxx@foxmail.com', description='log handler for send message to dingtalk', long_description=long_description, long_description_content_type='text/markdown', classifiers=[ 'Development Status :: 4 - Beta', 'Intended Audience :: Developers', 'Topic :: Software Development :: Libraries', 'Programming Language :: Python :: 3', # 省略一下 ], packages=find_packages(), python_requires='>=3.5', install_requires=[], project_urls={ 'Source': 'https://github.com/ruanimal/dingtalk-log-handler', }, )
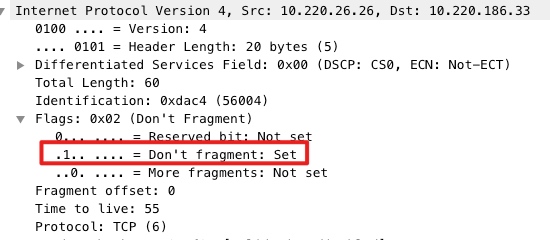
按我的知识,docker0是网桥,等价于交换机,除了性能问题,不应该导致丢包,就一直没往这个方向考虑(当然这块的知识也不扎实)。 MTU也不应该导致丢包,交换机应该会进行IP分片。 但忽略了一个点,虚拟的网桥并不是硬件网桥,可能并没有实现IP分片的逻辑(仅丢弃),又或者没有实现 PMTU(Path MTU Discovery)。 上面这点存疑,但更直接的原因是服务的IP包的 Don't fragment flag 为1,也就是禁止分片(为什么设置还不清楚)。
]]>编程GitSVNgmtime 在多线程环境使用引发的 bug/2021/04/15/gmtime-multi-thread-problem/话接上文,还是这个 C++ 模型服务,在并发请求的情况下,大概有0.01%的请求部分模型分数不对。定位这种问题,对一个Python程序员来说,真是苦手。还好,经过调整代码不断测试,最终完美解决了问题。
]]>编程LinuxDockerHomeBrew 与无 root 权限 Linux 环境包管理/2023/05/28/homebrew-as-non-root-package-manager/一些公用的 Linux 服务器,处于维护以及安全考虑,一般只会提供普通权限用户给使用者。 普通用户的权限满足日常使用是够了,但是难以配置自己的开发环境,安装一些自己需要的包。
cat <<EOF >> /etc/apt/sources.list.d/openmediavault.list deb https://packages.openmediavault.org/public usul main # deb https://downloads.sourceforge.net/project/openmediavault/packages usul main ## Uncomment the following line to add software from the proposed repository. # deb https://packages.openmediavault.org/public usul-proposed main # deb https://downloads.sourceforge.net/project/openmediavault/packages usul-proposed main ## This software is not part of OpenMediaVault, but is offered by third-party ## developers as a service to OpenMediaVault users. # deb https://packages.openmediavault.org/public usul partner # deb https://downloads.sourceforge.net/project/openmediavault/packages usul partner EOF
deftop(self): if self.length > 0: return self._items[1]
defdel_top(self): if self.length > 0: self.exch(1, self.length) val = self._items.pop() self.sink(1) return val
def__repr__(self): tmp = [] seq = ' ' for i in range(1, self.depth+1): l = seq.join([str(e) for e in self._items[2**(i-1):2**i]]) tmp.append(l) return'\n'.join(tmp)
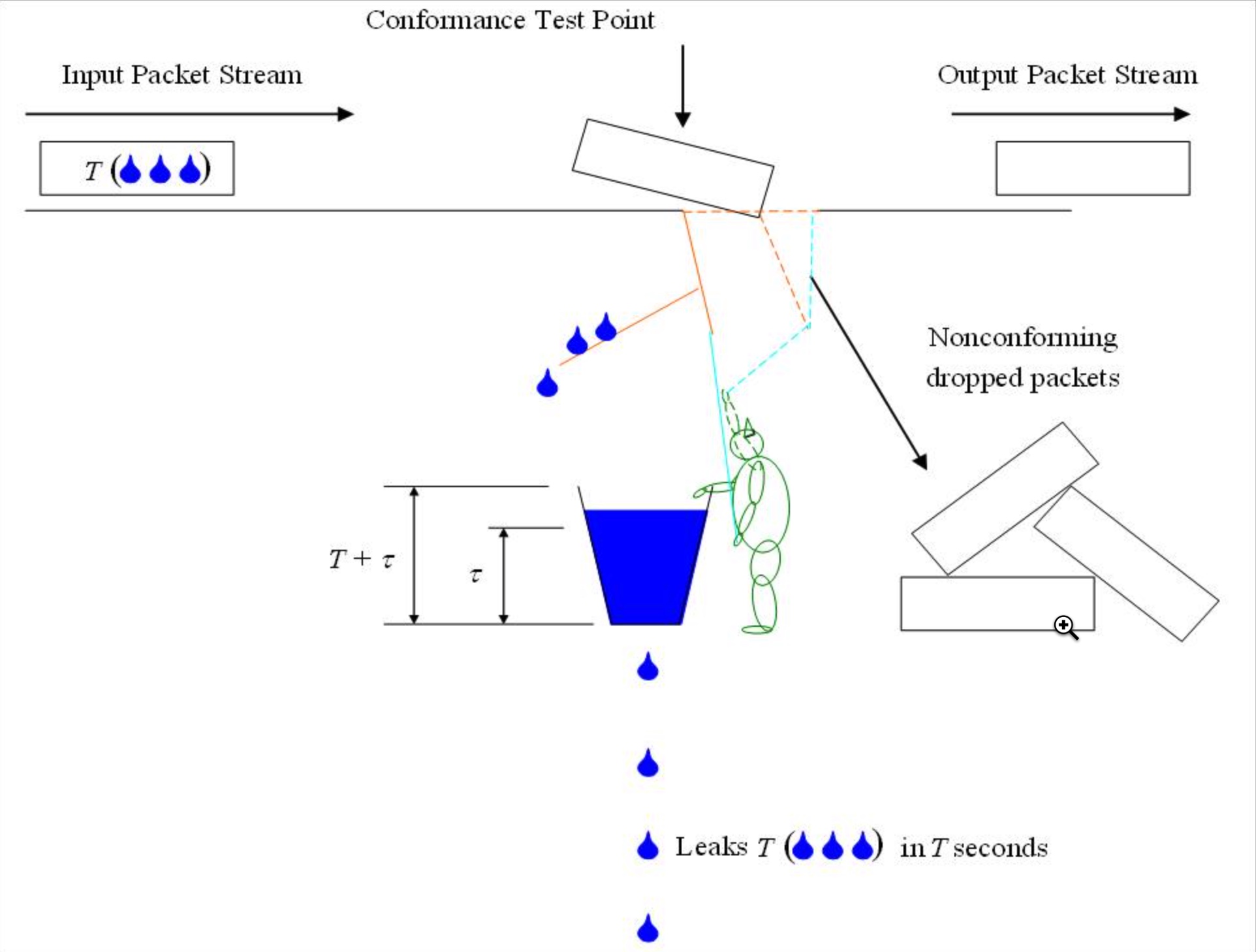
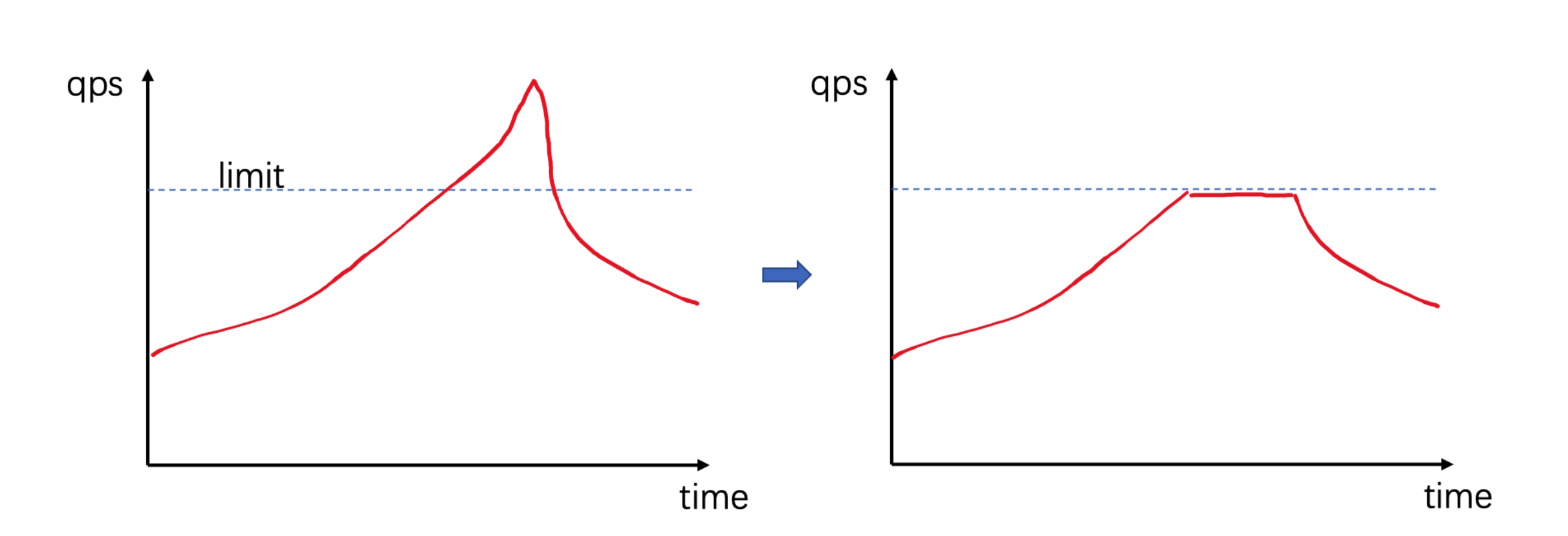
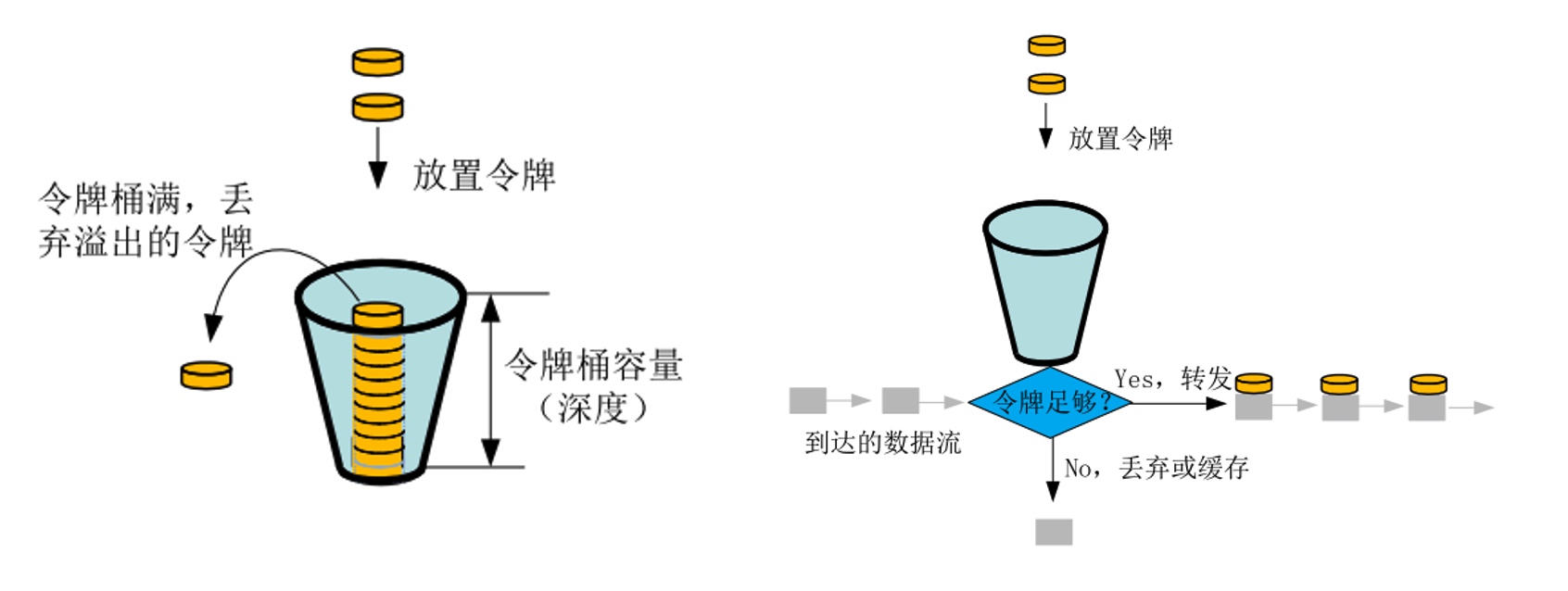
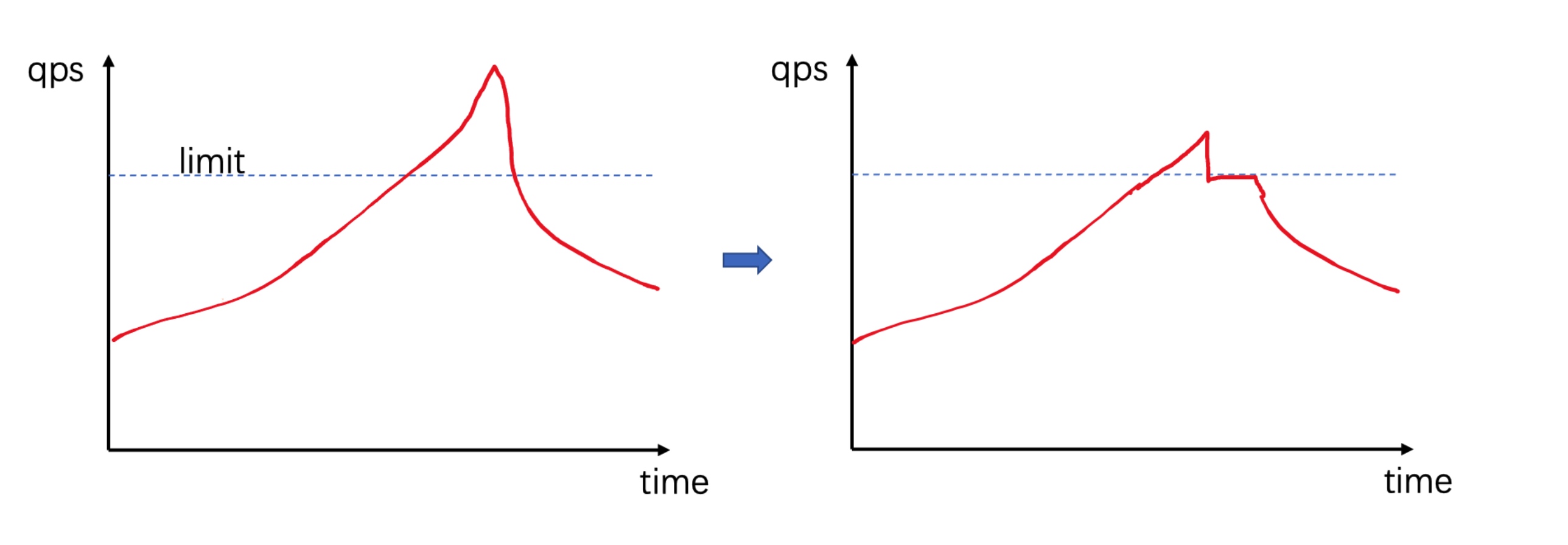
if __name__ == '__main__': rate_limiter = LeakyBucket(2) for i in range(10): if rate_limiter.acquire(block=False): print(time(), 'succ', i) else: print(time(), 'skip', i) sleep(0.2)
defconsume(self, tokens, block=True): assert tokens <= self.capacity, 'Attempted to consume {} tokens from a bucket with capacity {}'.format(tokens, self.capacity)
if block and tokens > self.tokens: deficit = tokens - self._tokens delay = deficit / self.fill_rate print('Have {} tokens, need {}; sleeping {} seconds'.format(self._tokens, tokens, delay)) sleep(delay)
if tokens <= self.tokens: self._tokens -= tokens returnTrue else: returnFalse
BASE=/srv/nfs_root TODAY=$(date +'%Y%m%d') USERS=( data ) # read -r -a USERS <<< $(groupmems -g users -l)
cd$BASE for share in $(ls); do for user in${USERS[@]}; do rec="$BASE/${share}/.recycle/$user" if [[ ! -d $rec ]]; then mkdir -p $rec fi cd$rec if [[ ! -d $TODAY ]]; then mkdir $TODAY fi if [[ -L today || -f today ]]; then rm -f today elif [[ -d today ]]; then mv today $TODAY/$(date +'bak.%s') fi ln -s ./$TODAY today done done
windows 系统中,增加定时任务,删除NFS共享目录中的回收站文件到系统回收站 Python 代码如下,超过一定时间的文件会被送到 windows 回收站
import time import os import logging from datetime import datetime, timedelta from pathlib import Path from send2trash import send2trash
defget_size(path: str) -> int: return sum(p.stat().st_size for p in Path(path).rglob('*'))
defmain(): exports = [] for line in open(EXPORTS_FILE): parts = line.strip().split() ifnot parts or parts[0].startswith('#'): continue exports.append(parts[0])
dt = (datetime.now() - timedelta(days=KEEP_DAYS)).strftime('%Y%m%d') for export in exports: for user in USERS: rec = os.path.join(export, '.recycle', user) if os.path.exists(rec): for item in os.listdir(rec): path = os.path.join(rec, item) # print(path, get_size(path)) if os.path.isdir(path) and item.startswith('2') and item < dt: size = get_size(path) if size <= 0: logging.info('rm empyt\t%s', path) os.rmdir(path) else: logging.info('trash\t%s', path) send2trash(path)
if __name__ == '__main__': whileTrue: try: logging.info('check') main() time.sleep(3600) except Exception as e: logging.exception(e)
# HTTP listen addresses, multiple allowed list listen_http 0.0.0.0:80 list listen_http [::]:80
# HTTPS listen addresses, multiple allowed list listen_https 0.0.0.0:443 list listen_https [::]:443
# Redirect HTTP requests to HTTPS if possible option redirect_https 1
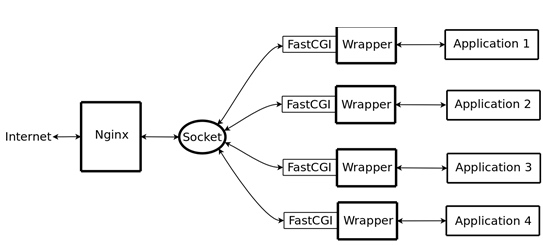
# Server document root option home /www # 此处省略其他配置 # List of extension->interpreter mappings. # Files with an associated interpreter can # be called outside of the CGI prefix anddo # not need to be executable. # list interpreter ".php=/usr/bin/php-cgi" # list interpreter ".cgi=/usr/bin/perl" list interpreter ".lua=/usr/bin/lua" # 我们添加的内容
asyncdefmain(): start = time.time() await asyncio.wait([hello_world(i) for i in range(8)]) end = time.time() print("Complete in {} seconds".format(end - start))
hello world 1533904346.37133 hello world 1533904346.371683 hello world 1533904346.37199 hello world 1533904346.372059 hello world 1533904346.372122 hello world 1533904346.372176 hello world 1533904346.372245 hello world 1533904346.372295 num 0 num 3 num 4 num 1 num 5 num 6 num 7 num 2 Complete in 4.015289068222046 seconds [Finished in 4.2s]
defdo_someting(): logging.info('begin call') import run
logging.info(repr(run.server)) logging.info('%s\t%s', (run.Server), id(run.Server)) if hasattr(run.server, 'name'): logging.info('found attr name') else: logging.info('not found attr name') logging.info('end call')
logging.info('end load')
再看执行python run.py的结果
[2020-06-2010:57:03,659run.<module> ] <module'__main__' from '/Volumes/study/Projects/code_snippet/circular_import/run.py'> [2020-06-2010:57:03,659run.<module> ] begin load [2020-06-2010:57:03,659run.<module> ] end load [2020-06-2010:57:03,662 foo.<module> ] begin load [2020-06-2010:57:03,662 foo.<module> ] end load [2020-06-2010:57:03,662run.start ] call [2020-06-2010:57:03,662run.start ] <__main__.Server object at 0x1064eb940> [2020-06-2010:57:03,662run.start ] <class '__main__.Server'> 140250245614784 [2020-06-2010:57:03,662 foo.do_someting] begin call [2020-06-2010:57:03,663run.<module> ] <module'__main__' from '/Volumes/study/Projects/code_snippet/circular_import/run.py'> [2020-06-2010:57:03,663run.<module> ] begin load [2020-06-2010:57:03,663run.<module> ] end load [2020-06-2010:57:03,663 foo.do_someting] <run.Server object at 0x1065d8b50> [2020-06-2010:57:03,663 foo.do_someting] <class 'run.Server'> 140250247610512 [2020-06-2010:57:03,663 foo.do_someting] not found attr name [2020-06-2010:57:03,663 foo.do_someting] end call
# dict.keys() - list(dict.keys()) - for city in city_dict.keys(): + for city in list(city_dict.keys()):
# dict.iteritems() -> dict.items() - for k, v in hawk_info.iteritems(): + for k, v in hawk_info.items(): # dict.items() -> list(dict.iteritems()) - for name, val in trans_td_schema.items(): + for name, val in list(trans_td_schema.items()):
# xrange -> list(range) - for index in xrange(len(rule_files)): + for index in range(len(rule_files)):
defbubble_sort(arry): n = len(arry) while n > 1: n -= 1 for x in range(n): if arry[x] > arry[x+1]: arry[x], arry[x+1] = arry[x+1], arry[x] return arry
改进版本
defbubble_sort(arry): n = len(arry) while n > 1: n -= 1 swap_flag = False# 增加一个标记,当排好序后直接退出 for x in range(n): if arry[x] > arry[x+1]: arry[x], arry[x+1] = arry[x+1], arry[x] swap_flag = True ifnot swap_flag: break return arry
defselection_sort(arry): n = len(arry) for i in range(0, n): min = i for j in range(i+1, n): if arry[j] < arry[min]: min = j arry[i], arry[min] = arry[min], arry[i] return arry
defInsertion_sort(arry): n = len(arry) for i in range(1, n): temp = arry[i] index = i for j in range(i-1, -1, -1): if temp < arry[j]: arry[j+1] = arry[j] index = j else: break arry[index] = temp return arry
defshell_sort(arry): n = len(arry) step = int(round(n/2.0)) while step > 0: for i in range(step, n): temp = arry[i] index = i for j in range(i-step, -1, -step): if temp < arry[j]: arry[j+step] = arry[j] index = j else: break arry[index] = temp step = int(round(step/2)) return arry
归并排序 MergeSort
介绍
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
defmerge_sort(arry): if len(arry) <= 1: return arry num = int(len(arry)/2) left = merge_sort(arry[:num]) right = merge_sort(arry[num:]) return merge(left, right)
defmerge(left, right): l, r = 0, 0#左右两个序列的指针 result = [] while l<len(left) and r<len(right): if left[l] < right[r]: result.append(left[l]) l += 1 else: result.append(right[r]) r += 1 result += left[l:] result += right[r:] return result
快速排序 QuickSort
介绍
快速排序使用分治法(Divide and conquer)策略来把一个序列(list)分为两个子序列(sub-lists)。一个序列大于基准,一个小于基准。再对这两个序列进行同样的操作,以此类推直到所有元素都排列好。
defbucket_sort(array): buckets = {i:0for i in range(1, 101)} # 100 bucket for i in array: buckets[i] += 1 result = [] for i in xrange(1,101): result.extend([i] * buckets[i]) return result
堆排序
介绍
堆排序在 top K 问题中使用比较频繁。堆排序是采用二叉堆的数据结构来实现的,虽然实质上还是一维数组。二叉堆是一个近似完全二叉树 。
a:3 3 3 3 b:3 <function main2.<locals>.<lambda> at 0x10ca30310> <function main2.<locals>.<lambda> at 0x10ca30310> <function main2.<locals>.<lambda> at 0x10ca303a0> <function main2.<locals>.<lambda> at 0x10ca303a0> <function main2.<locals>.<lambda> at 0x10ca30430> <function main2.<locals>.<lambda> at 0x10ca30430> c:<function main2.<locals>.<lambda> at 0x10ca30310> <function main2.<locals>.<lambda> at 0x10ca30430> 4 5 6 d:<function main2.<locals>.<lambda> at 0x10ca30310> 6
Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
>>> classPerson(object): ... total = 0 ... def__init__(self, name, age): ... self.name = name ... self.age = age ... Person.total = Person.total + 1 ... deftalk(self): ... print('My name is {}, I am {} years old.'.format(self.name, self.age))
>>> tom = Person('tom', 1)
>>> tom.talk() My name is tom, I am 1 years old. >>> Person.total 1
>>> jerry = Person('jerry', 2)
>>> jerry.talk() My name is jerry, I am 2 years old.
# 如果是window平台, 跳过该测试用例 @pytest.mark.skipif(sys.platform == "win32", reason="does not run on windows") classTestPosixCalls: deftest_function(self): "will not be setup or run under 'win32' platform"
error: List item 0 has incompatible type "str"; expected "float" error: Dict entry 0 has incompatible type "str": "int"; expected "str": "str" error: Argument 1 to"print_address" has incompatible type "List[object]"; expected "Tuple[str, int]"
500 Internal Server Error 服务器发生不可预期的错误,导致无法完成客户端的请求。
503 Service Unavailable 服务器当前不能够处理客户端的请求,在一段时间之后,服务器可能会恢复正常。
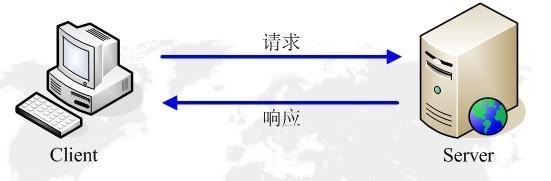
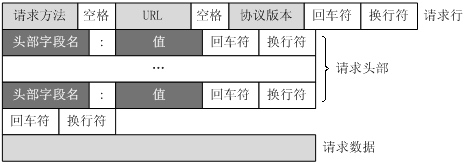
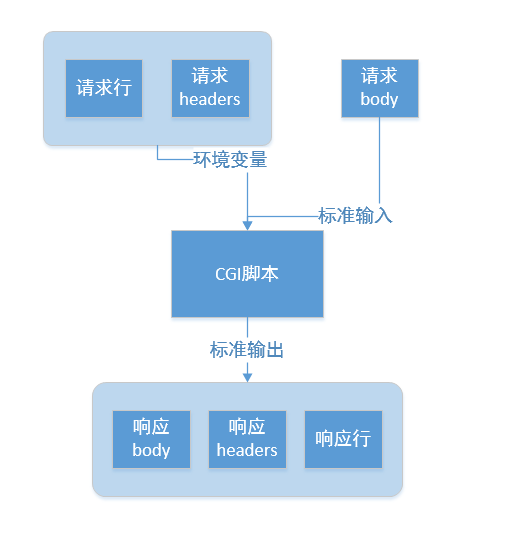
HTTP请求方法
HTTP1.1 版本
GET 请求指定的页面信息,并返回实体主体。 HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 PUT 从客户端向服务器传送的数据取代指定的文档的内容。 DELETE 请求服务器删除指定的页面。 CONNECTHTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 OPTIONS 允许客户端查看服务器的性能。 TRACE 回显服务器收到的请求,主要用于测试或诊断。
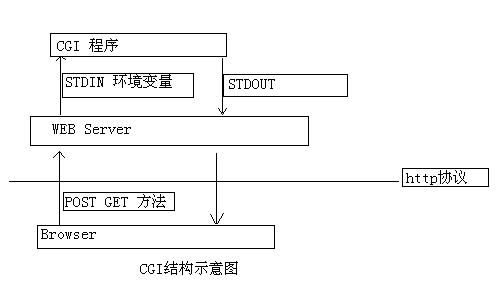
import cgi form = cgi.FieldStorage() text = form.getvalue('text', open('simple_edit.dat').read()) f = open('simple_edit.dat', 'w') f.write(text) f.close()
from django.utils.deprecation import MiddlewareMixin
classRemoteHostMiddleware(MiddlewareMixin): defprocess_view(self, request, view, args, kwargs): m = request.META if m.get("HTTP_X_REAL_IP"): ip = m.get("HTTP_X_REAL_IP") elif m.get('HTTP_X_FORWARDED_FOR'): x_forwarded_for = m.get('HTTP_X_FORWARDED_FOR') ip = x_forwarded_for.split(',')[0] else: ip = m.get('REMOTE_ADDR') request.remote_host = ip
deffunc(x=10): print'the beginning of function' if x <= 0ornot isinstance(x, int): return for i in range(x): print'before yield', i yield i print'after yield', i
➜ python aa.py ['/private/tmp/tmp1/abc', '/Users/ruan/.pyenv/versions/3.8.7/lib/python38.zip', '/Users/ruan/.pyenv/versions/3.8.7/lib/python3.8', '/Users/ruan/.pyenv/versions/3.8.7/lib/python3.8/lib-dynload', '/Users/ruan/.pyenv/versions/3.8.7/lib/python3.8/site-packages'] Traceback (most recent call last): File "aa.py", line 5, in <module> from b import * ModuleNotFoundError: No module named 'b'
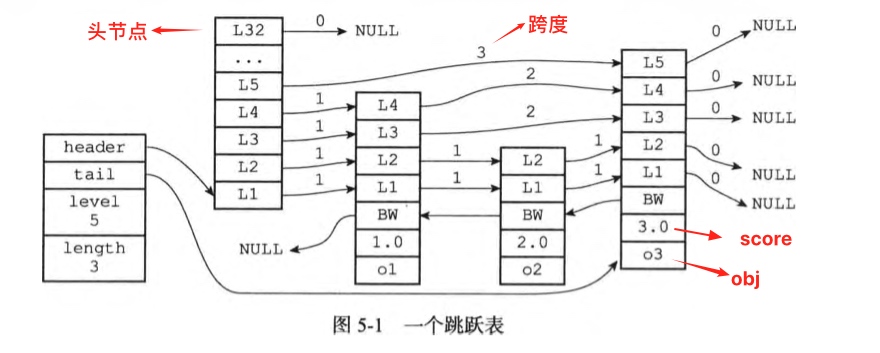
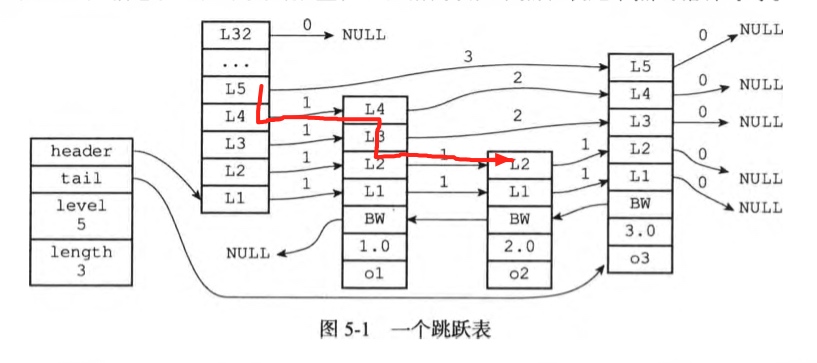
defzslGetRank(zsl: zskiplist, score: float, obj: robj) -> int: rank = 0 x = zsl.header for i in range(zsl.level-1, -1, -1): while x.level[i].forward and _node_lt(x.level[i].forward, score, obj): rank += x.level[i].span x = x.level[i].forward if x.obj and equalStringObjects(x.obj, obj): return rank return0
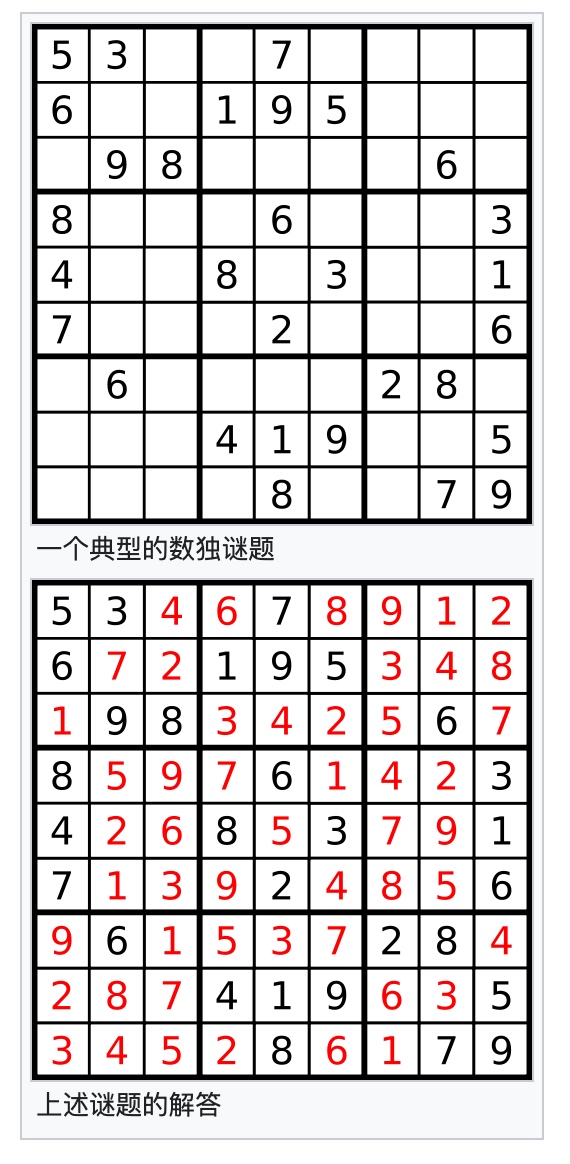
EMPTY = 0 defsodoku(board): defcan_put(board, row, col, c): for i in range(9): if board[i][col] != EMPTY and board[i][col] == c: # 行不冲突 returnFalse if board[row][i] != EMPTY and board[row][i] == c: # 列不冲突 returnFalse x, y = row // 3 * 3 + i // 3, col // 3 * 3 + i % 3 if board[x][y] != EMPTY and board[x][y] == c: # 九宫不冲突 returnFalse returnTrue
defsolve(board): for i in range(9): for j in range(9): if board[i][j] == EMPTY: for c in range(1, 10): if can_put(board, i, j, c): board[i][j] = c if solve(board): returnTrue else: board[i][j] = EMPTY returnFalse returnTrue return solve(board)
EMPTY = 0 defsodoku(board): defsolve(board): for i in range(9): for j in range(9): box_index = (i // 3 ) * 3 + j // 3 if board[i][j] == EMPTY: for c in (rows[i] & columns[j] & boxes[box_index]): # 通过集合来剪枝 # 设置状态 board[i][j] = c tmp = [False, False, False] for idx, elem in enumerate((rows[i], columns[j], boxes[box_index])): if c in elem: elem.remove(c) tmp[idx] = True # 进入下一层递归 if solve(board): returnTrue # 还原状态 board[i][j] = EMPTY for idx, elem in zip(tmp, (rows[i], columns[j], boxes[box_index])): if idx: elem.add(c) returnFalse returnTrue
# 验证题目是否合法, 初始化每一格可选择项 rows = [set(range(1,10)) for i in range(9)] # 行内所有点的可选值 columns = [set(range(1,10)) for i in range(9)] # 列 boxes = [set(range(1,10)) for i in range(9)] # 九宫 for i in range(9): for j in range(9): num = board[i][j] if num != EMPTY: num = int(num) box_index = (i // 3 ) * 3 + j // 3 if num notin rows[i]: returnFalse rows[i].remove(num) if num notin columns[j]: returnFalse columns[j].remove(num) if num notin boxes[box_index]: returnFalse boxes[box_index].remove(num) return solve(board)
Traceback (most recent calllast): ... File"/home/q/hawkeye_mid_dev/src/model/b_card_model.py", line 5, in <module> import numpy as np File"/home/sync360/miniconda3/envs/xd_mid/lib/python2.7/site-packages/numpy/__init__.py", line 142, in <module> from . import add_newdocs File"/home/sync360/miniconda3/envs/xd_mid/lib/python2.7/site-packages/numpy/add_newdocs.py", line 13, in <module> from numpy.lib import add_newdoc File"/home/sync360/miniconda3/envs/xd_mid/lib/python2.7/site-packages/numpy/lib/__init__.py", line 8, in <module> from .type_check import * File"/home/sync360/miniconda3/envs/xd_mid/lib/python2.7/site-packages/numpy/lib/type_check.py", line 11, in <module> import numpy.core.numeric as _nx File"/home/sync360/miniconda3/envs/xd_mid/lib/python2.7/site-packages/numpy/core/__init__.py", line 16, in <module> from . import multiarray KeyboardInterrupt OpenBLAS blas_thread_init: pthread_create: Resource temporarily unavailable OpenBLAS blas_thread_init: RLIMIT_NPROC 1024current, 516033max
Limit Soft Limit Hard Limit Units Max cpu time unlimited unlimited seconds Max file size unlimited unlimited bytes Max data size unlimited unlimited bytes Max stack size 10485760 unlimited bytes Max core file size 0 unlimited bytes Max resident set unlimited unlimited bytes Max processes 1024 516033 processes Max open files 32768 32768 files Max locked memory 65536 65536 bytes Max address space unlimited unlimited bytes Max file locks unlimited unlimited locks Max pending signals 516033 516033 signals Max msgqueue size 819200 819200 bytes Max nice priority 0 0 Max realtime priority 0 0 Max realtime timeout unlimited unlimited us
可以看到, Max processes一项的Soft Limit为1024, Hard Limit为516033, 与错误输出中的信息一致.
## select * from table11 session.query(SomeData).all() # return: [<__main__.SomeData object at 0x1040e6278>, <__main__.SomeData object at 0x103aa13c8>, <__main__.SomeData object at 0x103aa1438>]
## 通过主键获取数据 session.query(SomeData).get(1)
## select * from table11 where status='2' order by the_time limit 1 data = session.query(SomeData).filter_by(status='2').order_by(SomeData.the_time).first() # data: <__main__.SomeData object at 0x103aa13c8>
## select * from table11 where status in ('1', '2') session.query(SomeData).filter(SomeData.status.in_(['1', '2'])).all()
from contextlib import contextmanager from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker from sqlalchemy.orm import scoped_session # 使session可以用于多线程环境
# 使用示例 with get_session() as session: session.execute('select 1') session.add(SomeData(status='1', message='aa'))
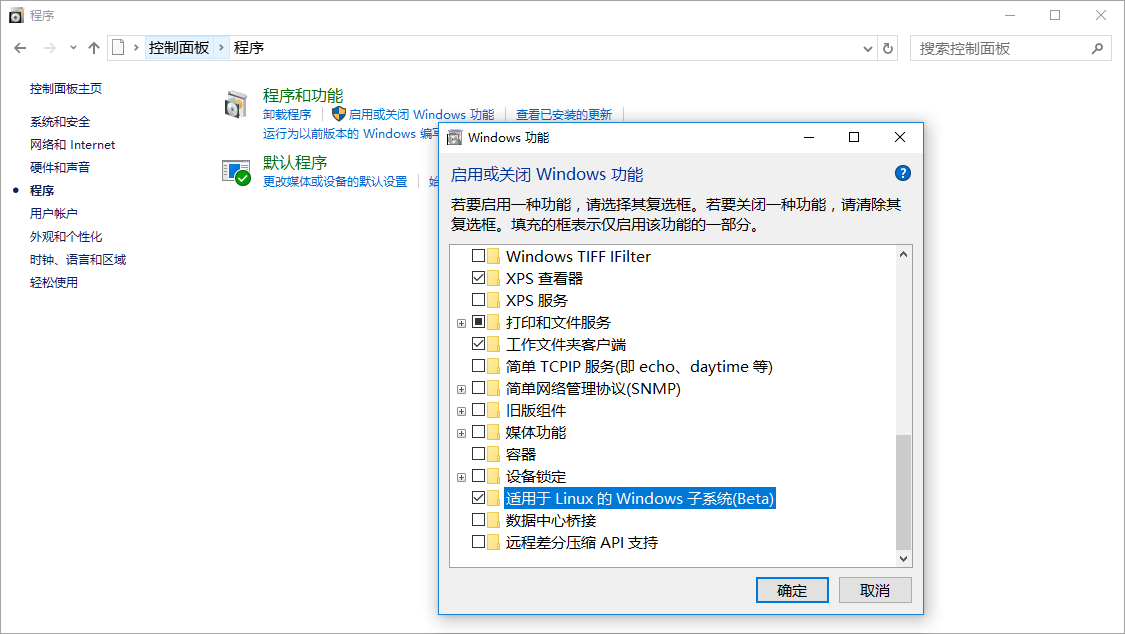
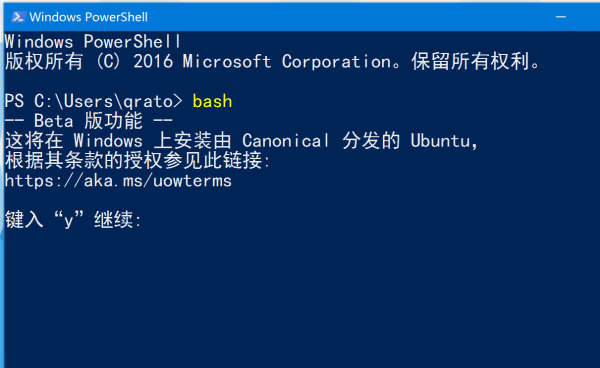
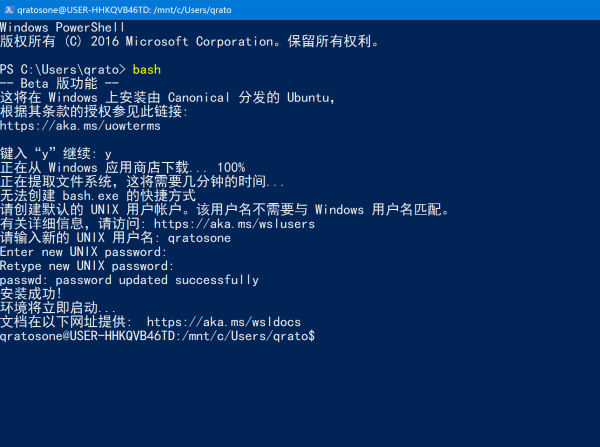
]]>编程PythonSQLAlchemyORMWindows Subsystem for Linux(WSL) 简单指引/2017/01/08/the-guide-of-windows-subsystem-for-linux/简介
Windows Subsystem for Linux(简称WSL)是一个为在Windows 10上能够原生运行Linux二进制可执行文件(ELF格式)的兼容层。它是由微软与Canonical公司合作开发,目标是使纯正的Ubuntu 14.04 “Trusty Tahr”映像能下载和解压到用户的本地计算机,并且映像内的工具和实用工具能在此子系统上原生运行。 WSL提供了一个微软开发的Linux兼容内核接口(不包含Linux代码),来自Ubuntu的用户模式二进制文件在其上运行。
inlinevoidPredLoopSpecalize(){ constint nthread = omp_get_max_threads(); InitThreadTemp(nthread, model.param.num_feature); for (bst_omp_uint i = 0; i < nsize - rest; i += K) { constint tid = omp_get_thread_num(); RegTree::FVec& feats = thread_temp[tid]; // thread_temp 为成员变量 // 省略其他逻辑 } }
inlinevoidInitThreadTemp(int nthread, int num_feature){ int prev_thread_temp_size = thread_temp.size(); if (prev_thread_temp_size < nthread) { thread_temp.resize(nthread, RegTree::FVec()); for (int i = prev_thread_temp_size; i < nthread; ++i) { thread_temp[i].Init(num_feature); } } }
修改后
inlinevoidPredLoopSpecalize(){ constint nthread = omp_get_max_threads(); std::vector<RegTree::FVec> local_thread_temp; // 改动点 int prev_thread_temp_size = local_thread_temp.size(); if (prev_thread_temp_size < nthread) { local_thread_temp.resize(nthread, RegTree::FVec()); for (int i = prev_thread_temp_size; i < nthread; ++i) { local_thread_temp[i].Init(model.param.num_feature); } } for (bst_omp_uint i = 0; i < nsize - rest; i += K) { constint tid = omp_get_thread_num(); RegTree::FVec& feats = local_thread_temp[tid]; // 改动点 // thread_temp 为成员变量 // 省略其他逻辑 } }
mkdir git-transfer cd git-transfer git --bare init
将中转仓库添加到本地项目的remote
git remote add transfer ssh://r@192.168.157.129/home/r/git-transfer/
给中转仓库添加hooks
cd /home/r/git-transfer/hooks/ cp post-update.sample post-update vi post-update
将 post-update 的内容修改为如下
#!/bin/sh # # An example hook script to prepare a packed repository for use over # dumb transports. # # To enable this hook, rename this file to "post-update".
unset GIT_DIR DeployPath=/home/r/git-dest
cd $DeployPath git add . -A && git stash git pull origin master
将中转仓库clone到目的项目
git clone /home/r/git-transfer/ /home/r/git-dest/
或者
cd git-dest git init git remote add origin /home/r/git-transfer/
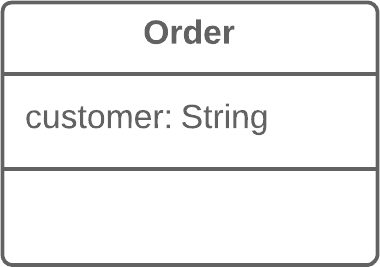
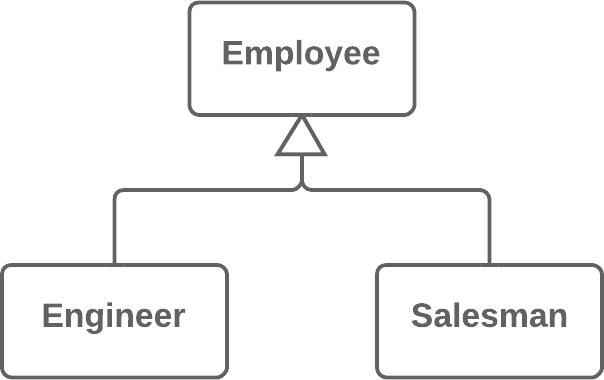
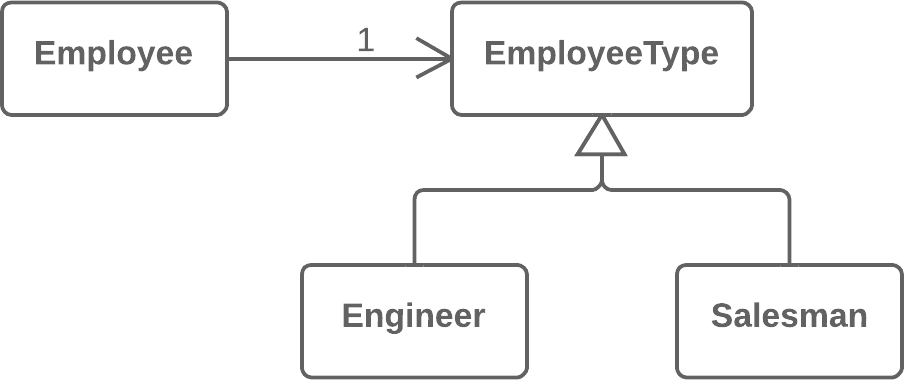
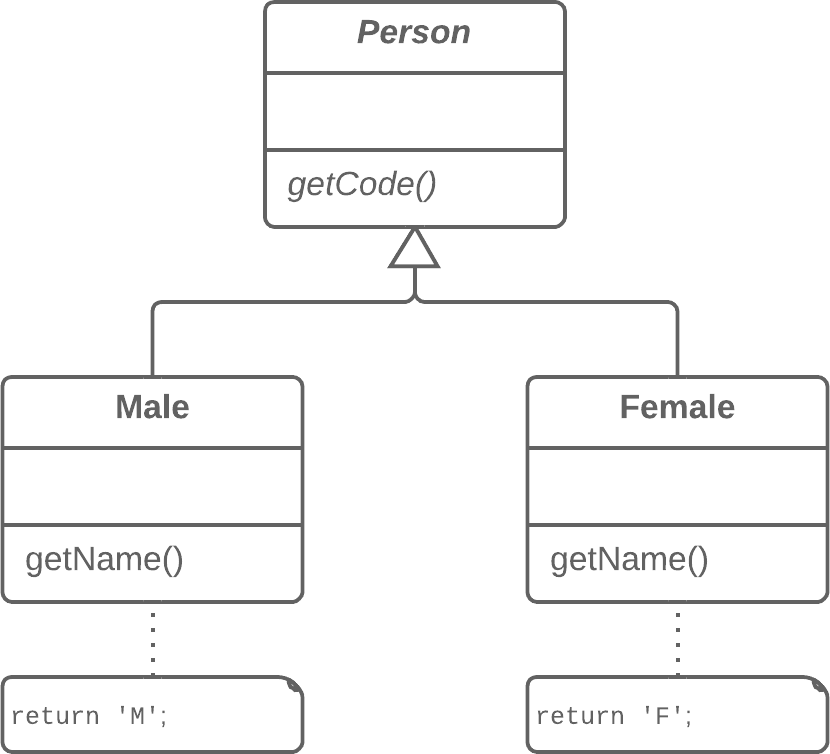
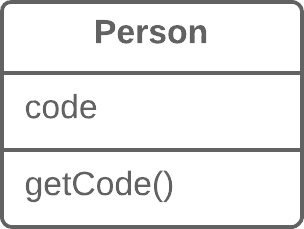
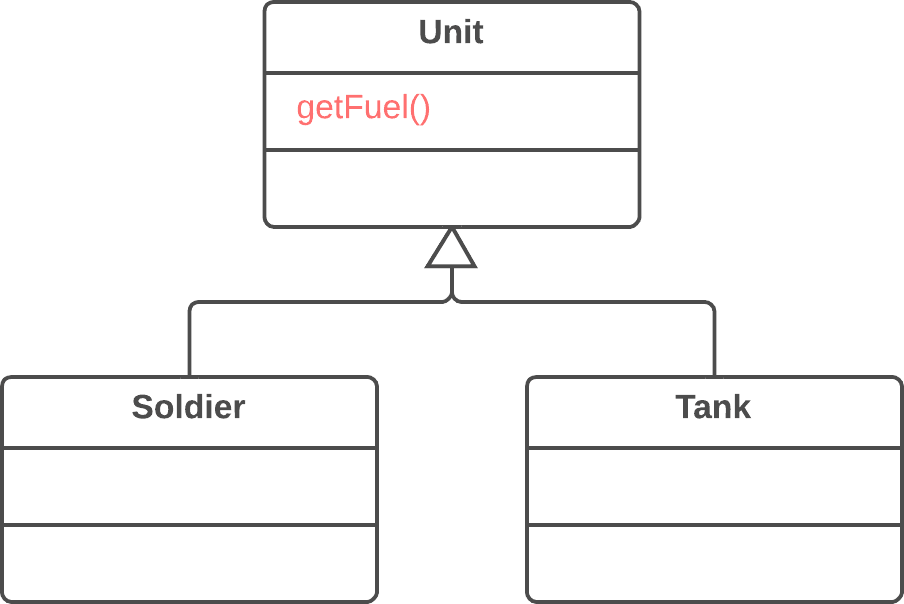
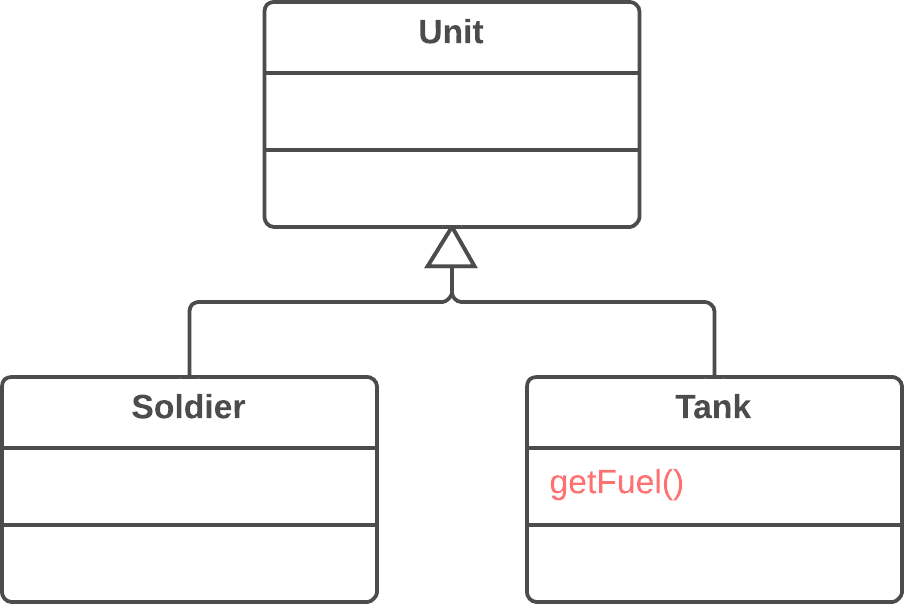
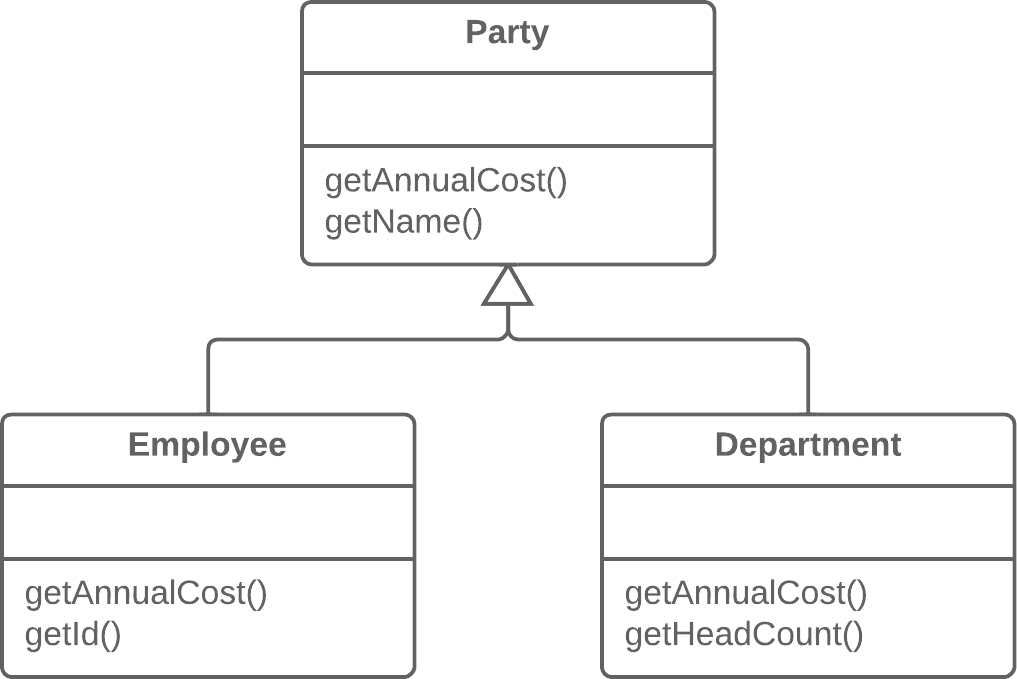
publicPriceCalculator(Order order){ // Copy relevant information from the // order object. }
publicdoublecompute(){ // Perform long computation. } }
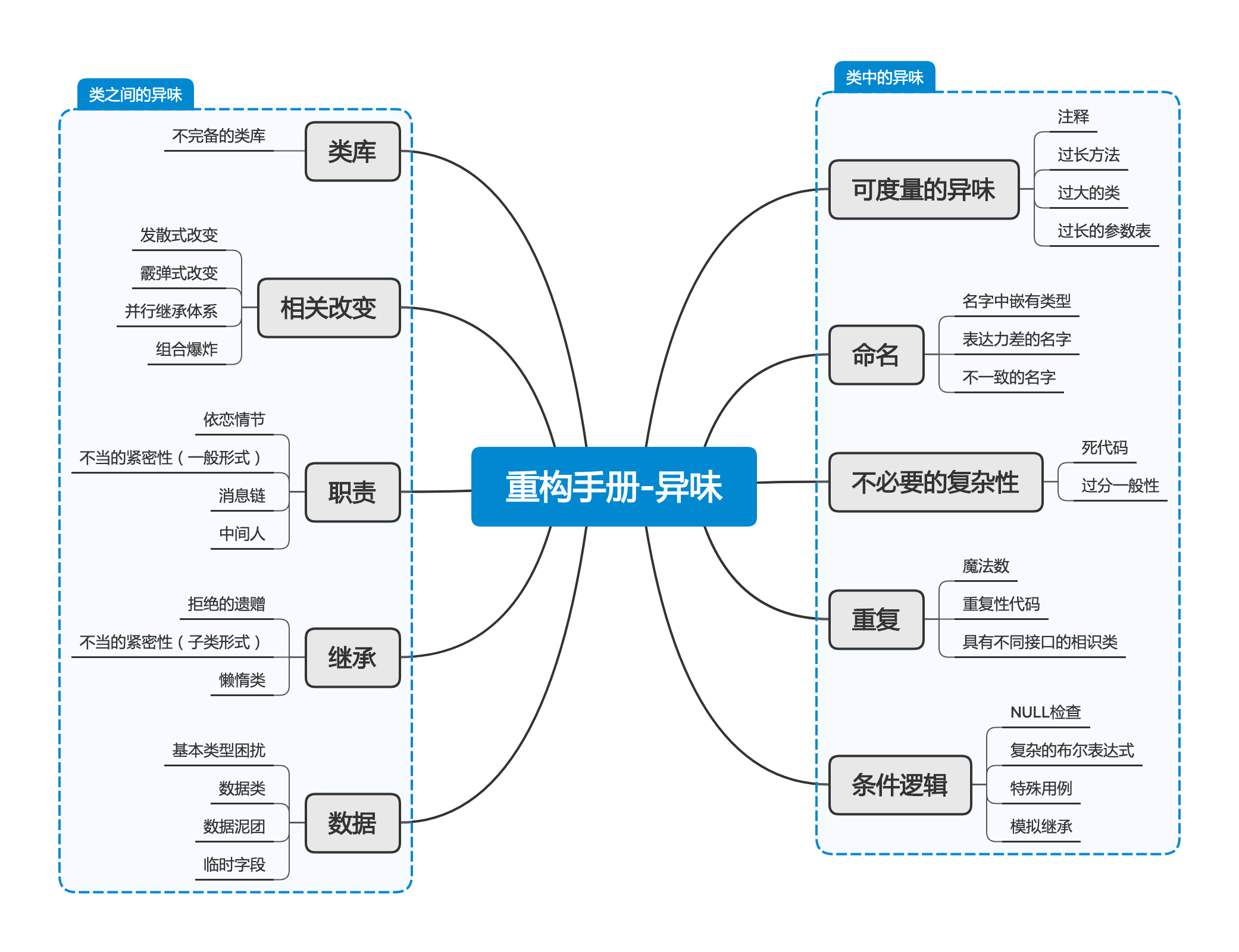
Substitute Algorithm:替换算法
before
String foundPerson(String[] people){ for (int i = 0; i < people.length; i++) { if (people[i].equals("Don")){ return"Don"; } if (people[i].equals("John")){ return"John"; } if (people[i].equals("Kent")){ return"Kent"; } } return""; }
after
String foundPerson(String[] people){ List candidates = Arrays.asList(new String[] {"Don", "John", "Kent"}); for (int i=0; i < people.length; i++) { if (candidates.contains(people[i])) { return people[i]; } } return""; }
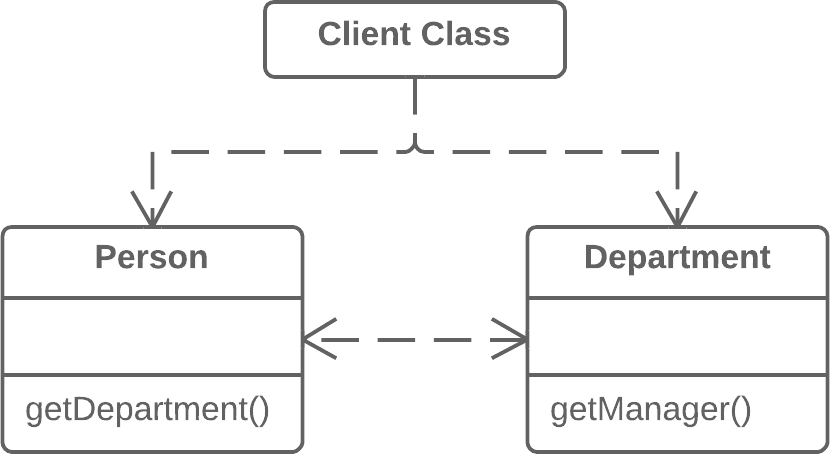
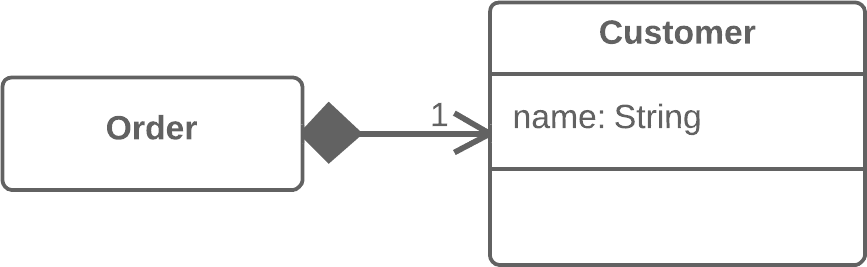
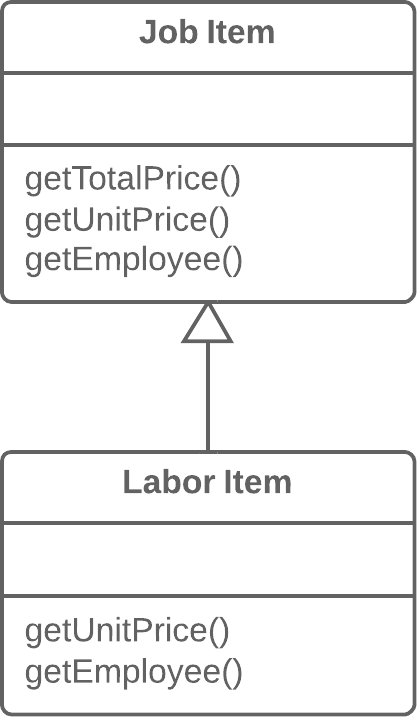
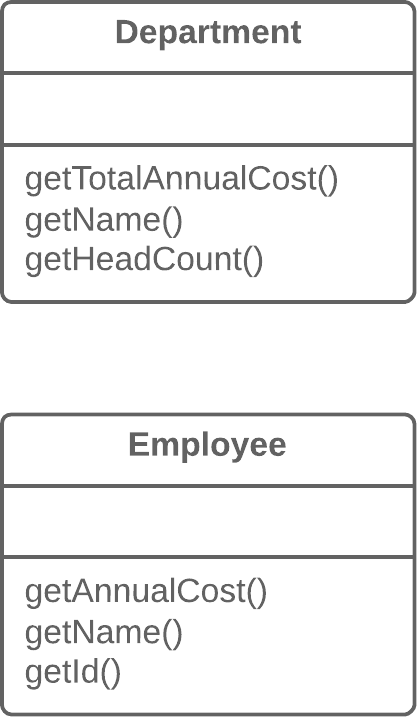
Moving Features between Objects:在对象之间搬移特性
Move Method:搬移方法
Move Field:搬移字段
Extract Class:抽取类
Inline Class:内联类
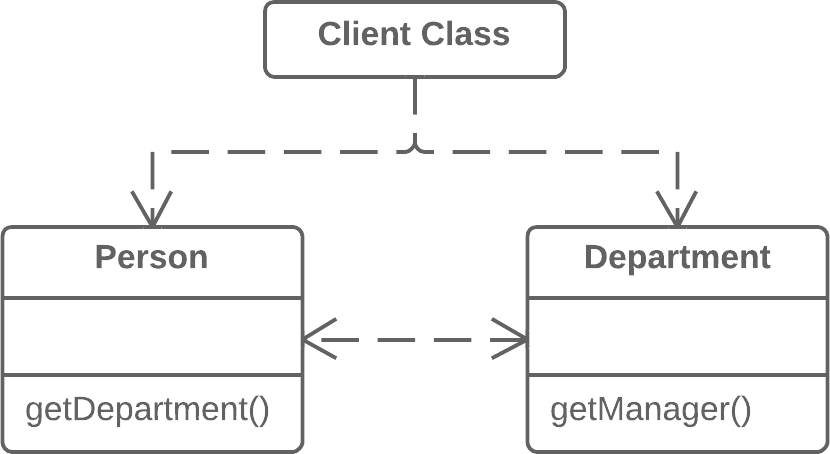
Hide Delegate:隐藏委托
Remove Middle Man:移除中间人
Introduce Foreign Method:引入外加函数
before
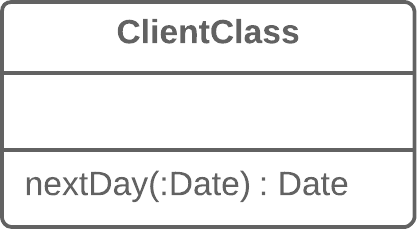
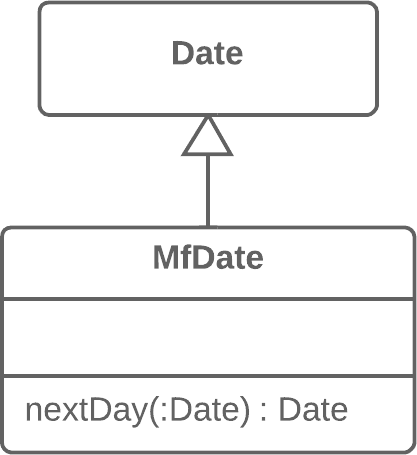
classReport{ // ... voidsendReport(){ Date nextDay = new Date(previousEnd.getYear(), previousEnd.getMonth(), previousEnd.getDate() + 1); // ... } }
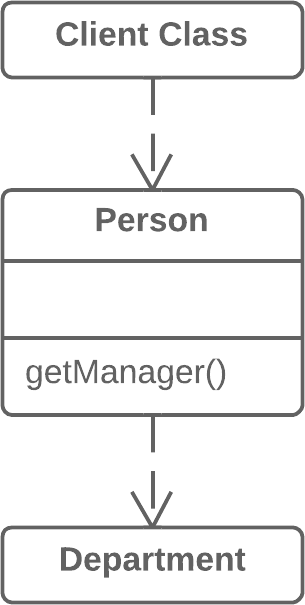
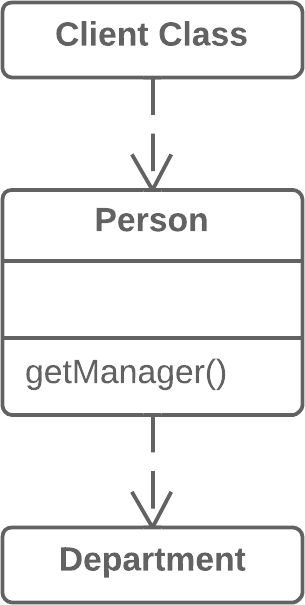
// Somewhere in client code speed = bird.getSpeed();
Remove Control Flag:移除控制标记
before
String foundMiscreant(String[] people){ String found = ""; for (int i = 0; i < people.length; i++) { if (found.equals("")) { if (people[i].equals ("John")){ sendAlert(); found = "John"; } } } return found; }
after
String foundMiscreant(String[] people){ for (int i = 0; i < people.length; i++) { if (found.equals("")) { if (people[i].equals ("John")){ sendAlert(); return"John"; } } } return""; }
Replace Nested Conditional with Guard Clauses:以卫语句取代嵌套条件式
before
publicdoublegetPayAmount(){ double result; if (isDead){ result = deadAmount(); } else { if (isSeparated){ result = separatedAmount(); } else { if (isRetired){ result = retiredAmount(); } else{ result = normalPayAmount(); } } } return result; }
after
publicdoublegetPayAmount(){ if (isDead){ return deadAmount(); } if (isSeparated){ return separatedAmount(); } if (isRetired){ return retiredAmount(); } return normalPayAmount(); }
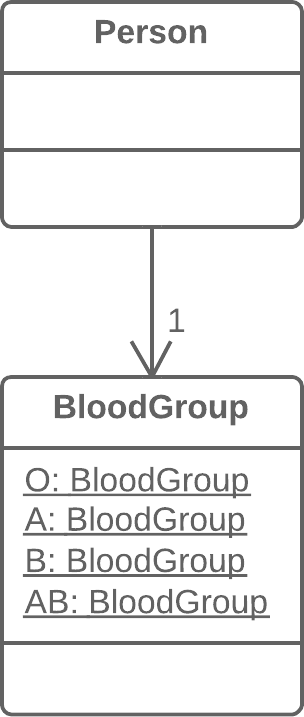
Introduce Null Object:引入Null对象
before
if (customer == null) { plan = BillingPlan.basic(); } else { plan = customer.getPlan(); }
after
classNullCustomerextendsCustomer{ booleanisNull(){ returntrue; } Plan getPlan(){ returnnew NullPlan(); } // Some other NULL functionality. }
// Replace null values with Null-object. customer = (order.customer != null) ? order.customer : new NullCustomer();
// Use Null-object as if it's normal subclass. plan = customer.getPlan();
Introduce Assertion:引入断言
before
doublegetExpenseLimit(){ // Should have either expense limit or // a primary project. return (expenseLimit != NULL_EXPENSE) ? expenseLimit : primaryProject.getMemberExpenseLimit(); }
defaltered(self): print"CHILD, BEFORE PARENT altered()" super(Child, self).altered() print"CHILD, AFTER PARENT altered()" dad = Parent() son = Child() dad.altered() son.altered()
classChild(object): def__init__(self): self.other = Other() defimplicit(self): self.other.implicit() defoverride(self): print"CHILD override()" defaltered(self): print"CHILD, BEFORE OTHER altered()" self.other.altered() print"CHILD, AFTER OTHER altered()"
son = Child() son.implicit() son.override() son.altered()
classMySQLConnectAdapter(object): def__init__(self, conn, cur): self._conn = conn self._cur = cur
def__getattribute__(self, name): if name in ('close', '_conn', '_cur'): return object.__getattribute__(self, name) else: return object.__getattribute__(self, '_cur').__getattribute__(name)